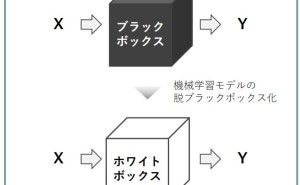
◆ データ分析の属人化を避けるためのメタ知識とデータカタログ
データ分析の特徴として、「属人化しやすい」という特徴があります。
なぜか属人化してしまい、一人ひとりやり方が異なり、分析ツールさえ異なるケースが多々あります。そもそもの、ローデータの加工の仕方まで異なったりします。どのようなやり方が良いのかは、もはや分からず、その人にとって最適と思われるやり方になっているのでしょう。しかし、共通化や共有化したほうがよさそうなことも多々あります。
属人化したものの多くは、メタ知識と呼ばれるものです。そして、メタ知識の多くはすぐに身につくものではありません。もちろん、共有化されたところで、すぐに身に着け活かすことは難しいかもしれません。しかし、知らずに個人の努力で身に着けるより、知っていて個人の努力で身に着けるほうが、身に着けるスピードは全然異なります。
今回は、「データ分析の属人化を避けるためのメタ知識とデータカタログ」というお話しをいたします。
1. データ分析のメタ知識とは
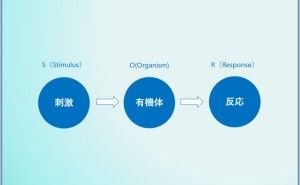
メタ知識とは、知識のための知識と言われています。例えば、やり方などの方法論です。
そのメタ知識をよく管理するために、ナレッジマネジメントなどの諸手法や、知識工学などの学術などがあります。今回はそのような小難しい話しはいたしません。データ分析で考えると、どのようなメタ知識があるでしょうか?
パッと思いつくのは、データ分析プロセス。他には、各分析手法の手続き、失敗例など。データという視点で見ると、ローデータがどのようなものなのかの知識や、そのデータの価値、データ加工の仕方などです。さらに、分析結果の見せ方や伝え方、活用の仕方などもメタ知識になることでしょう。
要するに、データ分析そのものやその活用を考える上で重要な知識全般になるわけです。その知識そのものが、データ分析やその活用を左右しかねない強力な力を持っています。例えば、データ分析の失敗事例を共有するだけで、人財の成長スピードが加速します。
単に、失敗を先取りできるだけでなく、失敗そのものが新たな価値になり資産化するため、失敗した者の心に「貢献感」が醸成されます。要するに、「失敗≒悪」ではなく「失敗≒資産」ということで気持ちが楽になるということです。
メタ知識には、負の経験(例:失敗例など)を価値というプラスに変えるパワーがあります。そして、データ分析のメタ知識の中で最も整備しやすいモノの中に、「データカタログ」というものがあります。
2. データカタログとは何か
最近、オープンデータの流通が増えています。
日本でも、政府や各自治体などで積極的にオープンデータを流通させる動きに出ています。例えば、DATA.GO.JPなどです。
その中で重要になってくるのが、データのカタログ化、データカタログを作ろうという動きがあります。ちなみに、データカタログとは、データそのまのではなく「データの名刺」のようなものです。要するに、データそのものではなくそのデータの「データカタログ」を流通させ、どのようなデータなのかを理解するできるようにし、そのデータカタログを見てそのデータが欲しいと考えたとき、はじめてそのデータを取得する、ということです。
すぐデータを取得できる場合もあれば、データカタログに記載されている機関に連絡しデータを請求するという場合にもあります。
データカタログは、オープンデータが先行していますが社内データでも活用できます。社内データをカタログ化することで、どのようなデータがどこにあり、どのようにすれば入手できるのかが分かるようになります。
データ分析を社内活用するとき、ぜひやっていただきたいと思います。いきなりすべての社内データをカタログ化することはできないかもしれませんが、必要なものから一つ一つカタログ化するのがよいでしょう。例えば、営業やマーケティング系のデータ(例:売上データ、販促データなど)は、カタログ化しやすいて思います。
3. データカタログとは、どのようなものなのか
HTMLなどのWeb技術の標準化団体であるW3C(World Wide Web Consortium)で、データカタログは標準化されています。DCAT(Data Catalog Vocabulary )と呼ばれ、実際に多くのオープンデータはDCATに準拠しています。
ちなみに、HTMLはハイパーリンクによってテキスト間の情報空間を構築しています。このようなデータカタログの試みはLOD(Linked Open Data、リンクト・オープン・データ)とも呼ばれ、データ同士をリンクさせるデータのウェブの構築をします。
DCATに準拠した形で社内データのカタログ化を進めればよい、ということになります。そうすることで、オープンデータとも連携が取りやすくなり、単に社内データだけの分析よりも幅が広がります。ちなみに、DCATはRDF(Resource Description Framework)と呼ばれるメタデータの記述方式で記述されています。
Apacheが、RDFのためのフリーの色々なツールを公開しています。Apache Jena(http://jena.apache.org/)です。例えば、RDFのクエリ言語であるSPARQLやRDFストアとしてFusekiというものがあります。FusekiにデータをロードしてSPARQL検索するという感じです。
ちょっと小難しい話しをしましたが、この辺りは社内SEや興味のありそうな方にお願いすればよいでしょう。重要なのは、DCATに準拠することです。では、具体的にどのようなデータ項目なのか? ということになりますが、RDFの形式で書かれたデータモデルを見ても、慣れていない方から見れば苦痛そのものです。
4. DATA.GO.JPの場合
政府のオープンデータサイトであるDATA.GO.JPの開発者向け情報(http://www.data.go.jp/for-developer/)で、ダウンロードしてみると、どのようなものか分かりやすいかと思います。何やら面倒な気もしますが、Apache Jenaでシステムを構築するかどうか以前に、Excelベースでもよいので、データの名刺であるデータカタログを整備するのがよいかと思います。
データ分析のメタ知識の中で、最も整備しやすいのが「データカタログ」です。このデータカタログを整備したら、次に、そのデータでどのような分析をしたのか、どのようなビジネス成果をだしたのか、などを追加情報と付け加えることで、データ分析のメタ知識の共通化や共有化が進み、属人化したものが赤裸々に表に現れてくることでしょう。
5. データカタログを整備してデータ分析活用を推進する
今回は、「データ分析の属人化を避けるためのメタ知識とデータカタログ...