ビジネス活動でよく目にするのが、時系列データです。この時系列データを使ったデータ分析・活用(データサイエンス実践)には、いくつかの種類があります。
他にもあるかもしれませんが、よく目にするのがこの3つです。今回は、「時系列データを使った3つのデータ活用」についてお話しします。
【目次】
1.時系列の異常検知
(1)時系列の分類
(2)時系列の予測
2.再帰(Recursive)予測
3.直接(Direct)予測
1.時系列の異常検知
「時系列の異常検知」は、営業であれば売上や受注、サイトであればページビューやコンバージョンなどモニタリングしている指標があるのなら、すぐにでもできるデータ分析・活用(データサイエンス実践)です。
通常は、異常検知対象データよりも過去のデータで数理モデルを構築し、異常検知を実施します。「時系列の異常検知」については、何度か触れている話題です。時系列解析用の数理モデルを使う場合と、時系列に特化していない線形回帰やツリー系、ニューラルネットワーク系の数理モデルを使う場合があります。
(1)時系列の分類
「時系列の分類」は、例えば工場のセンサーデータや心電図データなどの時系列の波形を分類するもので、異常な波形を抽出し分類するのなら異常検知になります。先ほどの異常検知で考えると、この分類の異常検知は、多変量の異常検知の問題になります。
通常は、異常・正常などのフラグ付けられた波形データ(時系列データ)で分類モデルを構築し、異常検知や予測をするというよりも、異常・正常によって波形パターンがどう異なるのか、その違いが何を意味すをるのかという分析をします。
その分析結果をもとに、異常検知や予測のための数理モデルの特徴量として活用することもありますし、何かしらの改善活動や施策につなげることもあります。
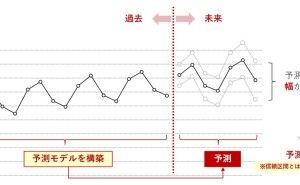
(2)時系列の予測
「時系列の予測」は、文字通り将来予測です。
時系列データを手にしたとき、先ず実施したくなるデータ分析・活用(データサイエンス実践)の1つでしょう。異常検知と同様に、時系列解析用の数理モデルを使う場合と、時系列に特化していない線形回帰やツリー系、ニューラルネットワーク系の数理モデルを使う場合があります。
どのような数理モデルを使うかという話題は脇に置いて、「どう予測するのか?」という視点で考えると、時系列データを使った予測の場合、大きく次の2種類があります。
- 再帰(Recursive)予測
- 直接(Direct)予測
通常は、同じタイプの数理モデル(アルゴリズム)ならば、「直接(Direct)予測」の方が予測精度は高くなります。ただし、「直接(Direct)予測」では使えない時系列解析用の数理モデルがあるという問題があります。
2.再帰(Recursive)予測
再帰予測とは、1つの数理モデルを使い1期先づつ予測するやり方です。最初の1期先は過去データを使い予測しますが…、2期先を予測するときには過去データと1期先の予測値を使い予測し…、3期先をを予測するときには過去データと1期先と2期先の予測値を使い予測します。
これを予測する期間分繰り返します。
この予測の仕方は、1つの数理モデルだけしか使わないため、計算コストが少なくて済みます。ただ、予測する先が遠い未来になるほど予測誤差が蓄積するため、予測する先が近い未来であれば問題ないですが、遠い未来になるとよくありません。
3.直接(Direct)予測
直接予測は、1つの数理モデルを使い1期先づつ予測するのではなく、1期先予測モデル・2期先予測モデル・3期先予測モデルなどといった感じで複数の数理モデルを使い予測します。
例えば……
月別データを使い5年先つまり60期(60カ月)先まで予測したい場合には60個の数理モデルを構築する必要があり、日別データを使い1年先つまり3...
65期(365日)まで予測したい場合には365個の数理モデルを構築する必要があります。
この予測の最大のメリットは、予測する先が遠い未来であっても予測誤差が蓄積されることがないことです。ただ、構築する数理モデルが多い場合に、計算コストが大きいという問題があります。
さらに、個々の数理モデルで出力された予測値同士の関係性が考慮されていないため、気持ち悪く感じる方もいることでしょう。目的変数が多変量な統計モデルを工夫し活用するか、ニューラルネットワーク系のモデルを使うか、幾つかやり方があります。