【目次】
【目次】
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
機械学習におけるデータの前処理は、モデルの性能に大きく影響を与える重要なステップです。特に、データの「標準化(Standardization)」と「正規化(Normalization)」は、多くのアルゴリズムの効果的な適用に不可欠です。これらの手法は、それぞれの適切な使用シナリオを理解することが重要です。今回は、標準化や正規化とは何なのかのお話しから始めて、これらの手法を掘り下げ、データセットや利用するアルゴリズムに応じて最適な前処理手法を選択するためのガイドラインを提供します。データサイエンスの初心者から中級者まで、より良いデータ分析とモデル開発のための洞察を得ることができるでしょう。
【記事要約】
標準化と正規化の重要性、それぞれの適用シナリオ、そして異なる正規化手法の選択肢をご理解いただけると思います。適切なデータ処理手法を選ぶことは、機械学習プロジェクトの成功に不可欠です。データの特性を正確に把握し、目的に合わせた正規化手法を選択することで、より精度の高いモデルを構築し、価値ある洞察を引き出すことが可能です。データサイエンスの旅は常に挑戦と発見の連続です。今回学んだ知識を活用して、自身のデータサイエンスプロジェクトに新たな視点をもたらし、さらなる高みを目指してください。
1. データサイエンスにおける前処理の重要性
(1)データの海から価値を引き出すアート
データサイエンスはデータの海から価値ある知見を引き出すアートです。このプロセスの核となるのが機械学習であり、データからパターンを学習し、予測や分類を行います。しかし、機械学習の効果は、使用されるデータの品質に大きく依存します。ここで前処理の役割が重要になります。
(2)前処理の役割とその影響
前処理は、生のデータを機械学習アルゴリズムが解釈しやすい形式に変換するプロセスです。前処理には、欠損値の処理、変数の変換、標準化や正規化などが含まれます。不適切な前処理はモデルの性能を大幅に低下させる可能性があります。一方、適切な前処理により、より正確で信頼性の高いモデルを構築できます。前処理は、データの品質を向上させ、モデルの学習に必要な情報を最大限に活用することを目的としています。特に、標準化と正規化は、データを一定の範囲や分布に調整することで、アルゴリズムがデータをより効率的に処理できるようにします。
2. 標準化の定義と適用場面
(1)標準化とは何か
標準化は、データセット内の各値を変換し、特徴量の平均が0、標準偏差が1になるように調整するプロセスです。この手法は、異なるスケールの特徴量を比較可能にし、機械学習モデルがデータをより効率的に処理できるようにします。数学的には、標準化は各データポイントxから特徴量の平均μを減算し、その結果を特徴量の標準偏差σで除算することで行われます。
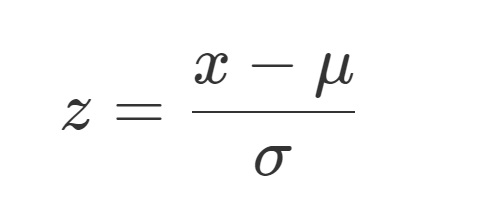
この変換で得られたzは、データは標準正規分布に従うようになります。
(2)標準化の適用例と利点
標準化は、特に特徴量が異なる単位を持つ場合や、大きく異なる範囲を持つ場合に有効です。例えば、ある特徴量がセンチメートルで、別の特徴がキログラムで測定されてい...
【目次】
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
機械学習におけるデータの前処理は、モデルの性能に大きく影響を与える重要なステップです。特に、データの「標準化(Standardization)」と「正規化(Normalization)」は、多くのアルゴリズムの効果的な適用に不可欠です。これらの手法は、それぞれの適切な使用シナリオを理解することが重要です。今回は、標準化や正規化とは何なのかのお話しから始めて、これらの手法を掘り下げ、データセットや利用するアルゴリズムに応じて最適な前処理手法を選択するためのガイドラインを提供します。データサイエンスの初心者から中級者まで、より良いデータ分析とモデル開発のための洞察を得ることができるでしょう。
【記事要約】
標準化と正規化の重要性、それぞれの適用シナリオ、そして異なる正規化手法の選択肢をご理解いただけると思います。適切なデータ処理手法を選ぶことは、機械学習プロジェクトの成功に不可欠です。データの特性を正確に把握し、目的に合わせた正規化手法を選択することで、より精度の高いモデルを構築し、価値ある洞察を引き出すことが可能です。データサイエンスの旅は常に挑戦と発見の連続です。今回学んだ知識を活用して、自身のデータサイエンスプロジェクトに新たな視点をもたらし、さらなる高みを目指してください。
1. データサイエンスにおける前処理の重要性
(1)データの海から価値を引き出すアート
データサイエンスはデータの海から価値ある知見を引き出すアートです。このプロセスの核となるのが機械学習であり、データからパターンを学習し、予測や分類を行います。しかし、機械学習の効果は、使用されるデータの品質に大きく依存します。ここで前処理の役割が重要になります。
(2)前処理の役割とその影響
前処理は、生のデータを機械学習アルゴリズムが解釈しやすい形式に変換するプロセスです。前処理には、欠損値の処理、変数の変換、標準化や正規化などが含まれます。不適切な前処理はモデルの性能を大幅に低下させる可能性があります。一方、適切な前処理により、より正確で信頼性の高いモデルを構築できます。前処理は、データの品質を向上させ、モデルの学習に必要な情報を最大限に活用することを目的としています。特に、標準化と正規化は、データを一定の範囲や分布に調整することで、アルゴリズムがデータをより効率的に処理できるようにします。
2. 標準化の定義と適用場面
(1)標準化とは何か
標準化は、データセット内の各値を変換し、特徴量の平均が0、標準偏差が1になるように調整するプロセスです。この手法は、異なるスケールの特徴量を比較可能にし、機械学習モデルがデータをより効率的に処理できるようにします。数学的には、標準化は各データポイントxから特徴量の平均μを減算し、その結果を特徴量の標準偏差σで除算することで行われます。
この変換で得られたzは、データは標準正規分布に従うようになります。
(2)標準化の適用例と利点
標準化は、特に特徴量が異なる単位を持つ場合や、大きく異なる範囲を持つ場合に有効です。例えば、ある特徴量がセンチメートルで、別の特徴がキログラムで測定されている場合、標準化によってこれらを同じスケールで比較できるようにします。また、多くの機械学習アルゴリズム、特に勾配降下法を使用するものでは、特徴量が同じスケールにあるとより高速に収束します。
3. 正規化の定義と適用場面
(1)正規化とは何か
正規化は、データポイントを一定の範囲にスケーリングするプロセスです。通常、この範囲は0から1、あるいは-1から1までです。正規化の主な目的は、異なるスケールを持つ特徴量を統一された範囲内に調整し、モデルの学習において各特徴量が均等に寄与するようにすることです。
(2)主な正規化手法
最も一般的な正規化の一つは、最小最大スケーリングです。

この方法により、データxは0と1の間にスケーリングされます。他には、平均正規化というものがあります。

これにより、データxは-1から1の範囲内にスケーリングされます。
(3)正規化の適用例と利点
正規化は、特に範囲が大きく異なる特徴量を持つデータセットで有効です。例えば、ある特徴が0から100の範囲で、別の特徴が0から1の範囲である場合、正規化によってこれらの特徴量を同じスケールに調整できます。これは、データが異なる単位で測定されている場合や、特徴量間でスケールが異なる場合に特に役立ちます。また、特定のアルゴリズム、特にニューラルネットワークや距離に基づくアルゴリズムでは、正規化されたデータがより良い性能を発揮することがあります。
4. 標準化と正規化の効果的な使い分け
(1)標準化と正規化の比較
標準化と正規化は、データをスケーリングする際に広く使われる二つの主要な手法です。標準化はデータの平均を0、標準偏差を1に変換するのに対し、正規化はデータを特定の範囲(例えば0から1)に収めます。これらの手法は、データの特性や使用するアルゴリズムによって適切に選択されるべきです。
(2)どちらを使うべきか
① 標準化の適用シナリオ
標準化は、特徴量が正規分布に近い場合や、アルゴリズムがデータの平均や分散に敏感な場合(例えば、線形回帰、ロジスティック回帰、サポートベクターマシンなど)に適しています。また、外れ値が存在し、それらに対してある程度の耐性を持たせたい場合にも有効です。
② 正規化の適用シナリオ
正規化は、データが固定範囲内に収まることが重要な場合(例えば、ニューラルネットワークの入力データとして)や、距離に基づくアルゴリズム(例えば、K-最近傍法やK-平均法)で使用される場合に適しています。これは、これらのアルゴリズムが特徴量間の絶対的なスケール差に敏感であるためです。
(3)組み合わせ使用の可能性
特定のシナリオでは、標準化と正規化を組み合わせて使用することも有効です。たとえば、データの一部に外れ値が存在し、かつ範囲が重要である場合、最初に標準化を行い、その後正規化を適用することで、データをより適切に処理できる可能性があります。
5. 他の主な正規化技術
(1)最大絶対値スケーリング
最大絶対値スケーリングは、各データポイントをその特徴量の最大絶対値で割る方法です。これにより、全ての特徴量は-1から1の範囲内に収まります。この方法は、データ内の0が意味を持つ場合や、スパースデータで有用です。
(2)ロバストスケーリング
ロバストスケーリングは、中央値と四分位範囲(IQR)を使用してデータをスケーリングします。これにより、外れ値の影響を受けにくくなるため、外れ値が多いデータセットに適しています。ロバストスケーリングは、外れ値に対する耐性を持ちつつ、データをより均一なスケールに変換します。
(3)ベクトルノルムスケーリング
ベクトルノルムスケーリングは、各データポイントをそのベクトルノルム(例えばユークリッドノルム)で割る方法です。これにより、データポイントはノルムに基づいてスケーリングされ、特にベクトルの大きさが重要な分析や処理に適しています。
(4)比較と選択
これらの正規化技術は、それぞれ異なるシナリオとデータ特性に適しています。最大絶対値スケーリングやロバストスケーリングは外れ値の影響を減らすことに重点を置いていますが、ベクトルノルムスケーリングはデータポイント間の距離や大きさを保持することに焦点を当てています。標準化や最小-最大スケーリングのような一般的な手法とこれらの技術を比較すると、選択はデータの特性と分析の目的に基づくべきです。たとえば、外れ値が問題となる場合はロバストスケーリングを、スパースデータを扱う場合は最大絶対値スケーリングを検討するのが良いでしょう。
(5)一覧表
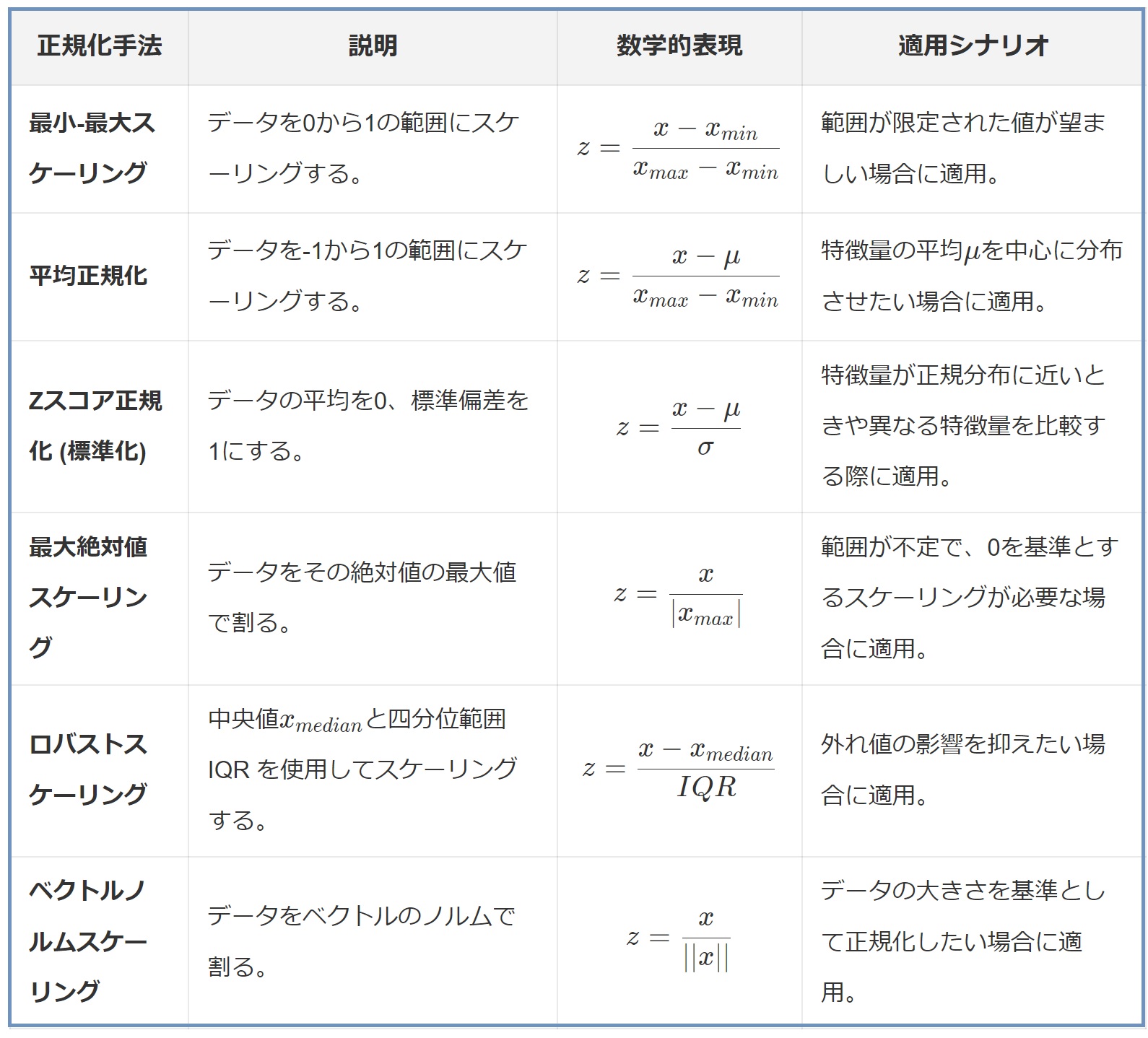
この表から分かる通り、標準化(Standardization)は、実際には正規化(Normalization)の一種としてまとめることも多いです。このようなとき、「Zスコア正規化」と呼ばれます。
6. 適切な方法選択
(1)最適な手法を選択するためのポイント
データ前処理は、機械学習プロジェクトの成功に不可欠です。適切な正規化手法を選択することは、モデルの精度と性能に大きな影響を与えます。以下は、異なるシナリオにおいてどの正規化手法が最適かを判断するための方法例です。
- データの特性を理解する
外れ値の有無、特徴量間のスケールの違い、データの分布など、データの基本的な特性を把握することが重要です。
- アルゴリズムの要件を考慮する
使用する機械学習アルゴリズムが特定のデータ分布やスケールに依存する場合、それに適した正規化手法を選択する必要があります。
- 目的に合わせた選択
例えば、距離に基づくアルゴリズムを使用する場合は、最小-最大スケーリングやロバストスケーリングが適しているかもしれません。反対に、正規分布を前提とするアルゴリズムでは、標準化が適切です。
- 複数の手法を試す
一つの手法に固執せず、異なる正規化手法を試し、どれが最良の結果をもたらすかを確認することも有効です。
(2)適切な手法を選択するための手順

この表は、データ処理の際に適切な正規化手法を選択するための一連の手順を示しています。データの特性やアルゴリズムの要件を理解し、目的に合わせて柔軟に正規化手法を選択することが重要です。また、実際に様々な手法を試して最良の結果を得るためには、実験的なアプローチが必要です。最終的には、モデルの性能と一般化能力を最大化するために、最適な手法を選択します。
(3)データ前処理の重要性と将来の展望
データ前処理は、機械学習においてしばしば見過ごされがちですが、モデルの性能を最大化するためには不可欠です。今後も、新しいアルゴリズムやデータの種類が登場するにつれて、データ処理手法も進化し続けるでしょう。したがって、常に最新の手法に精通し、フレキシブルなアプローチを取ることが重要です。
次回に続きます。
◆関連解説記事:データサイエンスとは?データサイエンティストの役割は?必要なツールも紹介
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!