▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
機械学習は、データから学ぶ技術です。しかし、実際のデータは完璧ではありません。特に、データセットにおける欠損データの問題は、機械学習プロジェクトにおいて避けられない課題です。欠損データをどのように扱うかは、モデルの性能に大きな影響を与えます。伝統的に、欠損データを扱う一般的な方法は「一変量代入法」です。この方法は、欠損値をその変数の平均値や中央値で置き換えるなど、単純明快であり、実装が容易です。しかし、これは各変数を独立して扱うため、変数間の関係を無視してしまうという欠点があります。ここで、より洗練されたアプローチとして「多変量代入法」が登場します。この方法は、欠損データのある変数と他の変数との関係を考慮に入れ、欠損値をより正確に推定しようと試みます。多変量代入法は、変数間の相関関係を利用して、欠損データを推測することにより、よりリアルなデータセットを作成することを目指しています。今回は「機械学習における多変量代入法:欠損データの克服」というお話しをします。
【記事要約】
多変量代入法は、欠損データを扱う上で非常に有効な手法です。医療データの分析、市場調査、金融リスクモデリングなど、多岐にわたる分野でその利用が見られます。この手法は、データの質と完全性を向上させ、変数間の複雑な関係性を考慮した正確なデータ補完を可能にします。しかし、データの種類やサイズの制限、計算コストなどの課題も存在します。テクノロジーの進化に伴い、これらの課題を克服し、より幅広い分野での応用が期待されています。データサイエンスの世界は常に進化しており、多変量代入法はその進化の一翼を担う重要なツールとなるでしょう。
1. 一変量代入法とその限界
機械学習におけるデータ処理の基本的なステップの一つに、欠損データの扱いがあります。データセットにおける欠損データの存在は避けられない問題であり、これを効果的に解決する方法の一つが「一変量代入法」です。一変量代入法は、欠損値をその変数の統計的な指標(例えば平均値、中央値、最頻値など)で置き換える方法です。この手法の主な利点はその単純さにあります。計算が容易で、実装も簡単です。特に、データセットが小さい場合や欠損値がランダムに分布している場合には、一変量代入法は有効なアプローチとなり得ます。しかし、一変量代入法には明確な限界も存在します。
- 変数間の相関の無視: 一変量代入法は、他の変数との関係を考慮しません。そのため、変数間に存在する相関関係やパターンを見逃す可能性があります。これは、データの本質的な特性や構造を適切に反映できないことを意味します。
- データ分布の歪み: 平均値や中央値で欠損値を置き換えると、データの分布が実際よりも狭くなり、分散が低下することがあります。これにより、モデルが過剰に単純化される可能性があり、結果として予測精度が低下することもあります。
- ランダムではない欠損データの扱い: データがランダムに欠損していない場合(例えば、特定の条件下でのみデータが欠損するなど)、一変量代入法は適切な解決策とはなりません。このような状況では、欠損が発生している理由を考慮した複雑な手法が必要となります。
一変量代入法は、その単純さから機械学習初心者や小規模プロジェクトに適していますが、限界も明確です。変数間の相関を無視するため、データの特性を見落とす可能性があります。また、データ分布の歪みやランダムでない欠損データの扱いにも弱点を持ちます。そのため、より複雑なデータセットや精度を要求される機械学習プロジェクトでは、多変量代入法などの高度な手法を検討する必要があります。
2. 多変量代入法とは何か?
多変量代入法の基本的な考え方は、データセット内の他の変数の情報を利用して、欠損データを推測することです。例えば、ある変数のデータが欠損している場合、他の変数のデータを用いて、欠損している値を予測します。これにより、データセット全体の統計的特性をより正確に保持することができます。多変量代入法には、欠損値を推定するためのさまざまな技術が存在します。代表的な方法としては、以下のようなものがあります。
回帰分析による欠損値の推定
回帰分析を用いた欠損値の推定は、他の変数との相関関係に基づいて欠損値を予測します。例えば、ある変数の欠損値が他の変数によって説明できる場合、その関係性を利用して欠損値を推定することができます。この方法は、変数間の関係を考慮するため、一変量代入法よりも精度が高いことが期待されます。
KNN (K-Nearest Neighbors)を用いたアプローチ
KNNは、欠損値のあるデータポイントに最も近いk個のデータポイントを見つけ、それらの値の平均を取ることで欠損値を推定します。この方法は、データの局所的な特性を利用するため、特にパターンが顕著なデータセットに適しています。しかし、データセットが非常に大きい場合や次元が多い場合、計算コストが高くなる可能性があります。
MICE (Multiple Imputation by Chained Equations)
MICEは、欠損値を持つ各変数に対して、他の変数を用いて複数の回帰モデルを構築し、これらのモデルを用いて欠損値を繰り返し推定する方法です。各ステップで欠損値を更新し、数回の繰り返しを通じて、より正確な推定値を得ることができます。この方法は、複数の変数にわたる欠損値を効果的に扱うことができ、複雑なデータ構造に対応する強みを持っています。
多変量代入法は、欠損データの問題を解決するための強力なツールです。回帰分析、KNN、MICEなどの異なるアプローチを用いることで、データセットの特性に応じて最適な欠損値推定方法を選択することができます。
3. 多変量代入法の具体的な手法
多変量代入法は、欠損データの問題を解決するための洗練されたアプローチです。この手法では、欠損データが存在する変数と他の変数との関係を利用して、より正確な欠損値の推定を行います。主な手法としては、先ほど取り上げた回帰分析、KNN (K-Nearest Neighbors)、MICE (Multiple Imputation by Chained Equations)などがあります。先ほどよりも、ちょっと詳しく説明します。
(1)回帰分析による欠損値の推定
回帰分析による欠損値の推定は、多変量代入法の中でも特に有効な手法の一つです。変数間の相関関係を考慮した推定を行うことで、データセットの欠損値をより精確に補完することができます。しかし、適切な変数の選定とモデルの構築は、この手法の成功において非常に重要な要素です。
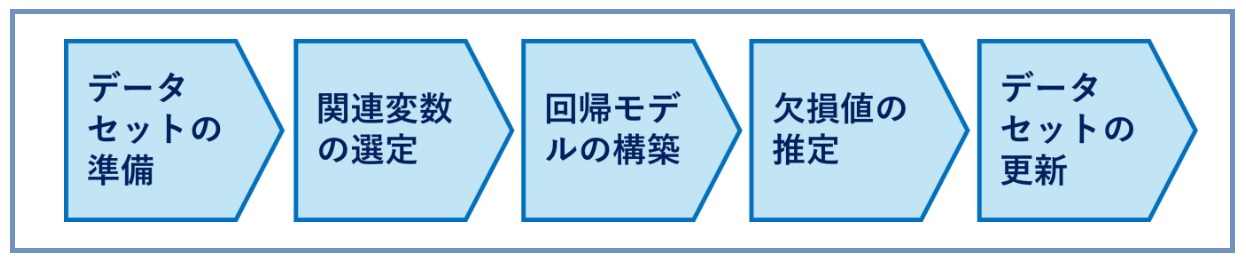
①基本的なプロセス
- データセットの準備: まず、データセット内で欠損が発生している変数と、その他の変数を特定します。
- 関連変数の選定: 欠損値の推定に用いる関連変数を選定します。この選定は、変数間の相関関係やドメイン知識に基づいて行われることが一般的です。
- 回帰モデルの構築: 欠損値のある変数を目的変数とし、選定した関連変数を説明変数として回帰モデルを構築します。このモデルは、線形回帰、ロジスティック回帰、またはより複雑な回帰モデルである可能性があります。
- 欠損値の推定: 構築した回帰モデルを使用して、欠損値を持つデータポイントに対して値を推定します。この推定値は、モデルが示す変数間の関係に基づいて計算されます。
データセットの更新: 推定された値を用いて、データセット内の欠損値を更新します。
②特性と利点
- 相関関係の活用: この手法は、変数間の相関関係を利用して欠損値を推定するため、一変量代入法よりもデータの特性をより適切に反映できます。
- 柔軟性: 線形回帰だけでなく、より複雑なモデルを使用することも可能です。これにより、非線形な関係や複雑なデータ構造にも対応できます。
- 精度の向上: 関連変数を適切に選定し、適切なモデルを構築することで、一変量代入法よりも正確な推定が可能になります。
③課題
- 変数選定の難しさ: 適切な関連変数の選定は、データの理解とドメイン知識に大きく依存します。
- モデルの複雑性: 使用する回帰モデルの複雑さによっては、計算コストが増加し、過学習のリスクも生じる可能性があります。
- データの偏り: 回帰分析は、データに偏りがある場合、誤った推定を行うリスクがあります。
(2)KNN (K-Nearest Neighbors)を用いたアプローチ
KNNを用いたアプローチは、欠損データ補完のための有効な手段の一つです。データの局所的な特性を利用することで、他の手法では捉えられないパターンや傾向を反映することができます。しかし、計算コストや適切なパラメータの選定、次元の呪いなど、考慮すべき課題も存在します。これらの要因を考慮に入れつつ、データセットの特性に合わせて適切に使用することが重要です。
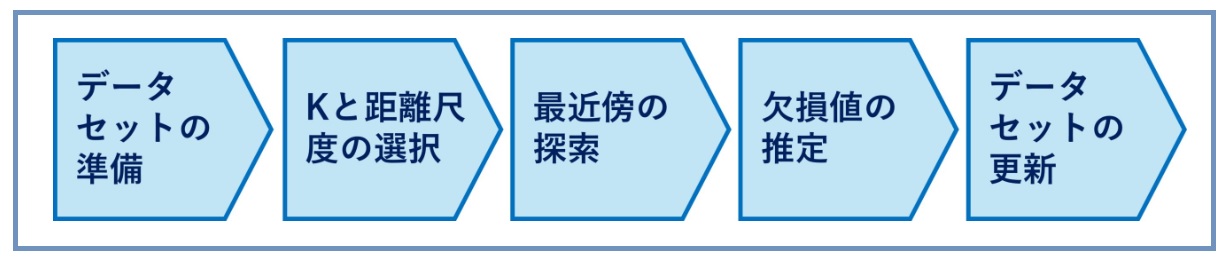
①基本的なプロセス
- データセットの準備: まず、データセット内で欠損が発生している変数と、その他の変数を特定します。
- Kと距離尺度の選択: KNNでは、最初に「K」の値を選定します。Kは、欠損値の推定に使用する近傍データポイントの数を指します。さらに、欠損値のあるデータポイントに最も近いデータポイントを見つけるために、距離尺度(例:ユークリッド距離)を選択します。
- 最近傍の探索: 欠損値を含む各データポイントについて、選定した距離尺度を用いて、最も近いK個のデータポイント(近傍)を探索します。
- 欠損値の推定: 近傍のデータポイントの値を用いて欠損値を推定します。数値データの場合は、これらの値の平均や中央値を取ることが一般的です。カテゴリーデータの場合は、最も頻繁に現れるカテゴリーを選択します。
- データセットの更新: 推定された値を用いて、データセット内の欠損値を更新します。
②特性と利点
- データの局所的な特性の利用: KNNはデータの局所的な特性を利用するため、特定のパターンやクラスタがデータセット内に存在する場合に特に効果的です。
- 柔軟性: 数値データだけでなく、カテゴリーデータの欠損値の補完にも適用可能です。
- 直感的で理解しやすい: KNNの原理は直感的であり、理解しやすいため、実装と解釈の両方が比較的容易です。
③課題
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
機械学習は、データから学ぶ技術です。しかし、実際のデータは完璧ではありません。特に、データセットにおける欠損データの問題は、機械学習プロジェクトにおいて避けられない課題です。欠損データをどのように扱うかは、モデルの性能に大きな影響を与えます。伝統的に、欠損データを扱う一般的な方法は「一変量代入法」です。この方法は、欠損値をその変数の平均値や中央値で置き換えるなど、単純明快であり、実装が容易です。しかし、これは各変数を独立して扱うため、変数間の関係を無視してしまうという欠点があります。ここで、より洗練されたアプローチとして「多変量代入法」が登場します。この方法は、欠損データのある変数と他の変数との関係を考慮に入れ、欠損値をより正確に推定しようと試みます。多変量代入法は、変数間の相関関係を利用して、欠損データを推測することにより、よりリアルなデータセットを作成することを目指しています。今回は「機械学習における多変量代入法:欠損データの克服」というお話しをします。
【記事要約】
多変量代入法は、欠損データを扱う上で非常に有効な手法です。医療データの分析、市場調査、金融リスクモデリングなど、多岐にわたる分野でその利用が見られます。この手法は、データの質と完全性を向上させ、変数間の複雑な関係性を考慮した正確なデータ補完を可能にします。しかし、データの種類やサイズの制限、計算コストなどの課題も存在します。テクノロジーの進化に伴い、これらの課題を克服し、より幅広い分野での応用が期待されています。データサイエンスの世界は常に進化しており、多変量代入法はその進化の一翼を担う重要なツールとなるでしょう。
1. 一変量代入法とその限界
機械学習におけるデータ処理の基本的なステップの一つに、欠損データの扱いがあります。データセットにおける欠損データの存在は避けられない問題であり、これを効果的に解決する方法の一つが「一変量代入法」です。一変量代入法は、欠損値をその変数の統計的な指標(例えば平均値、中央値、最頻値など)で置き換える方法です。この手法の主な利点はその単純さにあります。計算が容易で、実装も簡単です。特に、データセットが小さい場合や欠損値がランダムに分布している場合には、一変量代入法は有効なアプローチとなり得ます。しかし、一変量代入法には明確な限界も存在します。
- 変数間の相関の無視: 一変量代入法は、他の変数との関係を考慮しません。そのため、変数間に存在する相関関係やパターンを見逃す可能性があります。これは、データの本質的な特性や構造を適切に反映できないことを意味します。
- データ分布の歪み: 平均値や中央値で欠損値を置き換えると、データの分布が実際よりも狭くなり、分散が低下することがあります。これにより、モデルが過剰に単純化される可能性があり、結果として予測精度が低下することもあります。
- ランダムではない欠損データの扱い: データがランダムに欠損していない場合(例えば、特定の条件下でのみデータが欠損するなど)、一変量代入法は適切な解決策とはなりません。このような状況では、欠損が発生している理由を考慮した複雑な手法が必要となります。
一変量代入法は、その単純さから機械学習初心者や小規模プロジェクトに適していますが、限界も明確です。変数間の相関を無視するため、データの特性を見落とす可能性があります。また、データ分布の歪みやランダムでない欠損データの扱いにも弱点を持ちます。そのため、より複雑なデータセットや精度を要求される機械学習プロジェクトでは、多変量代入法などの高度な手法を検討する必要があります。
2. 多変量代入法とは何か?
多変量代入法の基本的な考え方は、データセット内の他の変数の情報を利用して、欠損データを推測することです。例えば、ある変数のデータが欠損している場合、他の変数のデータを用いて、欠損している値を予測します。これにより、データセット全体の統計的特性をより正確に保持することができます。多変量代入法には、欠損値を推定するためのさまざまな技術が存在します。代表的な方法としては、以下のようなものがあります。
回帰分析による欠損値の推定
回帰分析を用いた欠損値の推定は、他の変数との相関関係に基づいて欠損値を予測します。例えば、ある変数の欠損値が他の変数によって説明できる場合、その関係性を利用して欠損値を推定することができます。この方法は、変数間の関係を考慮するため、一変量代入法よりも精度が高いことが期待されます。
KNN (K-Nearest Neighbors)を用いたアプローチ
KNNは、欠損値のあるデータポイントに最も近いk個のデータポイントを見つけ、それらの値の平均を取ることで欠損値を推定します。この方法は、データの局所的な特性を利用するため、特にパターンが顕著なデータセットに適しています。しかし、データセットが非常に大きい場合や次元が多い場合、計算コストが高くなる可能性があります。
MICE (Multiple Imputation by Chained Equations)
MICEは、欠損値を持つ各変数に対して、他の変数を用いて複数の回帰モデルを構築し、これらのモデルを用いて欠損値を繰り返し推定する方法です。各ステップで欠損値を更新し、数回の繰り返しを通じて、より正確な推定値を得ることができます。この方法は、複数の変数にわたる欠損値を効果的に扱うことができ、複雑なデータ構造に対応する強みを持っています。
多変量代入法は、欠損データの問題を解決するための強力なツールです。回帰分析、KNN、MICEなどの異なるアプローチを用いることで、データセットの特性に応じて最適な欠損値推定方法を選択することができます。
3. 多変量代入法の具体的な手法
多変量代入法は、欠損データの問題を解決するための洗練されたアプローチです。この手法では、欠損データが存在する変数と他の変数との関係を利用して、より正確な欠損値の推定を行います。主な手法としては、先ほど取り上げた回帰分析、KNN (K-Nearest Neighbors)、MICE (Multiple Imputation by Chained Equations)などがあります。先ほどよりも、ちょっと詳しく説明します。
(1)回帰分析による欠損値の推定
回帰分析による欠損値の推定は、多変量代入法の中でも特に有効な手法の一つです。変数間の相関関係を考慮した推定を行うことで、データセットの欠損値をより精確に補完することができます。しかし、適切な変数の選定とモデルの構築は、この手法の成功において非常に重要な要素です。
①基本的なプロセス
- データセットの準備: まず、データセット内で欠損が発生している変数と、その他の変数を特定します。
- 関連変数の選定: 欠損値の推定に用いる関連変数を選定します。この選定は、変数間の相関関係やドメイン知識に基づいて行われることが一般的です。
- 回帰モデルの構築: 欠損値のある変数を目的変数とし、選定した関連変数を説明変数として回帰モデルを構築します。このモデルは、線形回帰、ロジスティック回帰、またはより複雑な回帰モデルである可能性があります。
- 欠損値の推定: 構築した回帰モデルを使用して、欠損値を持つデータポイントに対して値を推定します。この推定値は、モデルが示す変数間の関係に基づいて計算されます。
データセットの更新: 推定された値を用いて、データセット内の欠損値を更新します。
②特性と利点
- 相関関係の活用: この手法は、変数間の相関関係を利用して欠損値を推定するため、一変量代入法よりもデータの特性をより適切に反映できます。
- 柔軟性: 線形回帰だけでなく、より複雑なモデルを使用することも可能です。これにより、非線形な関係や複雑なデータ構造にも対応できます。
- 精度の向上: 関連変数を適切に選定し、適切なモデルを構築することで、一変量代入法よりも正確な推定が可能になります。
③課題
- 変数選定の難しさ: 適切な関連変数の選定は、データの理解とドメイン知識に大きく依存します。
- モデルの複雑性: 使用する回帰モデルの複雑さによっては、計算コストが増加し、過学習のリスクも生じる可能性があります。
- データの偏り: 回帰分析は、データに偏りがある場合、誤った推定を行うリスクがあります。
(2)KNN (K-Nearest Neighbors)を用いたアプローチ
KNNを用いたアプローチは、欠損データ補完のための有効な手段の一つです。データの局所的な特性を利用することで、他の手法では捉えられないパターンや傾向を反映することができます。しかし、計算コストや適切なパラメータの選定、次元の呪いなど、考慮すべき課題も存在します。これらの要因を考慮に入れつつ、データセットの特性に合わせて適切に使用することが重要です。
①基本的なプロセス
- データセットの準備: まず、データセット内で欠損が発生している変数と、その他の変数を特定します。
- Kと距離尺度の選択: KNNでは、最初に「K」の値を選定します。Kは、欠損値の推定に使用する近傍データポイントの数を指します。さらに、欠損値のあるデータポイントに最も近いデータポイントを見つけるために、距離尺度(例:ユークリッド距離)を選択します。
- 最近傍の探索: 欠損値を含む各データポイントについて、選定した距離尺度を用いて、最も近いK個のデータポイント(近傍)を探索します。
- 欠損値の推定: 近傍のデータポイントの値を用いて欠損値を推定します。数値データの場合は、これらの値の平均や中央値を取ることが一般的です。カテゴリーデータの場合は、最も頻繁に現れるカテゴリーを選択します。
- データセットの更新: 推定された値を用いて、データセット内の欠損値を更新します。
②特性と利点
- データの局所的な特性の利用: KNNはデータの局所的な特性を利用するため、特定のパターンやクラスタがデータセット内に存在する場合に特に効果的です。
- 柔軟性: 数値データだけでなく、カテゴリーデータの欠損値の補完にも適用可能です。
- 直感的で理解しやすい: KNNの原理は直感的であり、理解しやすいため、実装と解釈の両方が比較的容易です。
③課題
- 大規模データセットでの計算コスト: 特にデータセットが大きい場合、全てのデータポイント間で距離を計算する必要があるため、計算コストが高くなります。
- 適切なKの選定: 適切なKの値を選択することは非常に重要ですが、これは問題によって異なります。小さすぎるとノイズの影響を受けやすく、大きすぎるとデータの局所的特性を捉えられなくなります。
- 次元の呪い: 多次元データにおいては、KNNの性能が低下する可能性があります。これは「次元の呪い」として知られており、各次元間の距離が無意味になる可能性があります。
(3)MICE (Multiple Imputation by Chained Equations)
MICEは、特に複雑なデータセットにおいて、欠損データを扱うための強力な手段です。「多重代入」を基本とした手法であり、欠損データを一度に補完するのではなく、複数回にわたって反復的に代入することで推定を行います。このアプローチは、変数間の相関関係を考慮し、データの分布をより正確に反映させることができます。しかし、その計算コストやモデル選定の難しさも考慮に入れる必要があります。データセットの特性や分析の目的に応じて適切に使用することが重要です。
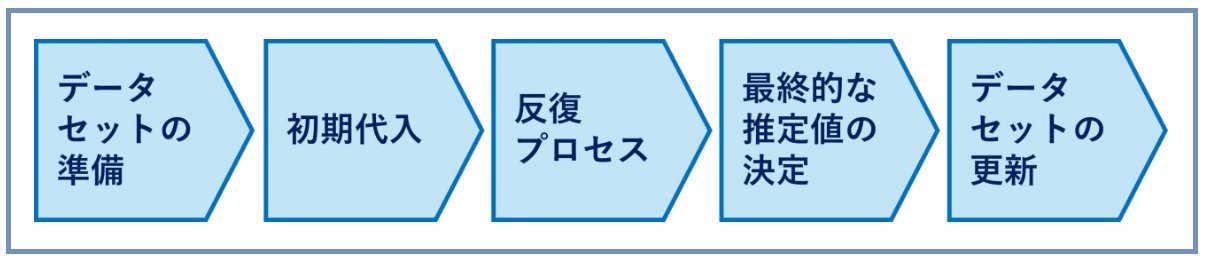
①基本的なプロセス
- データセットの準備: まず、データセット内で欠損が発生している変数と、その他の変数を特定します。
- 初期代入: まず、欠損値を初期値(例えば変数の平均値)で埋めます。
- 反復プロセス: 欠損値が存在する各変数に対して、以下のステップを繰り返します。一般的に、このプロセスは数回(例えば5回から10回)行われます。
- 変数の選定: 欠損値を持つ一つの変数を選択します。
- 回帰モデルの構築: 選択した変数を目的変数とし、他の変数を説明変数として回帰モデルを構築します。このとき、他の変数は以前のステップで代入された値を使用します。
- 欠損値の代入: 構築したモデルを用いて、選択した変数の欠損値を推定し、これで欠損値を更新します。
- 最終的な推定値の決定: 反復プロセスを通じて得られた複数の推定値のセットから、最終的な推定値を決定します。
- データセットの更新: 推定された値を用いて、データセット内の欠損値を更新します。
②特性と利点
- 変数間の相関の考慮: MICEは、変数間の関係を考慮して欠損値を推定するため、データの本質的な特性をより正確に反映できます。
- 柔軟性: 線形回帰モデルだけでなく、ロジスティック回帰や他のモデルを使用することも可能です。
- データの分布の保持: 多重代入により、データの分布特性をより正確に維持することができます。
③課題
- 計算コスト: MICEは反復的なプロセスを要するため、計算コストが高い場合があります。
- パラメータ選定の難しさ: 適切な回帰モデルの選定や反復回数の決定は、手法の成功において重要ですが、これが難しい場合があります。
4. 多変量代入法の利点
多変量代入法は、欠損データの扱いにおいて重要な役割を果たします。この手法は、変数間の関係性を考慮に入れることで、より正確なデータセットの補完を可能にします。以下、主な利点です。
- 変数間の関係性の保持: 多変量代入法は、変数間の関係性を考慮するため、データの本質的な特性をより正確に反映することができます。
- データの分布の維持: この手法は、データの全体的な分布を保持することに重点を置いており、特に統計的分析において重要です。
- 欠損データのより良い推定: 多変量代入法により、欠損データの推定値は、一変量代入法よりも精度が高くなる傾向があります。
- 複数の手法の適用可能性: 回帰分析、KNN、MICEなど、さまざまな手法が存在し、データセットの特性に応じて最適なものを選択することができます。
それぞれについて、もう少し詳しく説明します。
利点1:変数間の関係性の保持
多変量代入法の最大の利点の一つは、変数間の関係性を保持する能力にあります。データセットにおける各変数は、しばしば他の変数と相関関係にあるため、これらの関係性を考慮に入れることは、データの本質的な特性をより正確に捉えるために非常に重要です。
一変量代入法では、各変数を独立して扱い、他の変数との関連を考慮しません。これに対し、多変量代入法では、複数の変数間の相関を分析し、それに基づいて欠損データを補完します。これにより、データセット全体の特性や構造がより正確に表現され、結果的にデータ分析の質が向上します。
利点2:データの分布の維持
多変量代入法のもう一つの重要な利点は、データの全体的な分布を維持する能力です。統計的分析において、データの分布は基本的な前提となり、その正確性は分析結果の信頼性に直結します。一変量代入法では、欠損値を変数の平均値や中央値などで置き換えることが一般的ですが、これはデータの元の分布を歪める可能性があります。特に、データが特定のパターンや傾向を示している場合、これらの特性は一変量代入法では捉えられないことがあります。
対照的に、多変量代入法は、欠損データを補完する際に変数間の関係性を利用するため、元のデータ分布をより忠実に保持することができます。これにより、データセット全体の統計的特性が維持され、より正確な分析結果を得ることが可能になります。データの分布を維持することは、特に変数間の相関関係や相互作用が重要な分析において、非常に重要な要素です。
利点3:欠損データのより良い推定
多変量代入法のもう一つの重要な利点は、欠損データの推定値が一変量代入法よりも精度が高いという点です。この高精度は、変数間の相関関係を利用することにより実現されます。一変量代入法では、欠損値をその変数の統計的指標(例えば平均値)で単純に置き換えますが、これは変数間の関係性を考慮に入れていません。その結果、データセット全体としての精度や一貫性が損なわれる可能性があります。
多変量代入法では、他の変数との関係を考慮して欠損値を推定します。例えば、変数Aの欠損値を推定する際に、変数BとCの値を利用することで、より正確な推定値を得ることができます。これは、変数間の相関やパターンを反映した推定値を導出するため、結果としてより現実に即したデータセットが生成されます。これは、特に予測モデルの訓練や統計的分析において、非常に重要です。
このように、多変量代入法は欠損データの推定において高い精度を実現し、より信頼性の高いデータセットを提供します。
利点4:複数の手法の適用可能性
多変量代入法のもう一つの大きな利点は、さまざまな手法を適用できる柔軟性です。この手法は単一のアプローチに限定されず、データセットの特性や分析の目的に応じて最適な手法を選択することができます。主要な手法としては、先ほど紹介した回帰分析、KNN(K-Nearest Neighbors)、MICE(Multiple Imputation by Chained Equations)などがあります。
これらの手法は、データの種類、欠損パターン、分析の目的に応じて選択されます。例えば、線形関係が強いデータセットでは回帰分析が適しており、局所的なパターンが重要な場合はKNNが適しています。MICEは、より複雑なデータセットや複数の変数にわたる欠損データを扱う際に有効です。
このように、多変量代入法はその柔軟性により、さまざまなデータセットと分析ニーズに対応できる強力なツールです。適切な手法を選択し適用することで、欠損データの問題を効果的に解決し、より正確で信頼性の高い分析結果を得ることが可能になります。
5. 多変量代入法の課題
多変量代入法は、欠損データの扱いにおいて重要な役割を果たします。しかし、その複雑性によりいくつかの課題も存在します。以下、主な課題です。
- 複雑性と計算コスト: 多変量代入法は、一変量代入法よりも複雑であり、計算コストが高くなる可能性があります。
- モデル選択とパラメータの調整: 適切な手法やパラメータの選定は、データの特性と目的に基づいて慎重に行う必要があります。間違った選択は、推定精度に悪影響を与えることがあります。
- 過剰なデータ補完: 特にMICEのような手法では、過剰なデータ補完によって、元のデータの特性が歪む可能性があります。
- データの種類とサイズの制限: すべての種類のデータや大規模なデータセットに適用することが難しい場合があります。特に、高次元のデータでは「次元の呪い」による問題が生じる可能性があります。
それぞれについて、もう少し詳しく説明します。
課題1:複雑性と計算コスト
多変量代入法は、その性質上、一変量代入法よりもはるかに複雑です。この複雑さは、特に計算コストの面で顕著に現れます。多変量代入法では、欠損データのある各変数間の相関関係を考慮に入れる必要があるため、計算処理が増加します。特に、MICEのような反復的な手法では、データセットを何度も通過し、欠損値を推定するための複数のモデルを構築し直す必要があります。
この手法の計算コストは、データセットのサイズや変数の数に大きく依存します。変数が多く、データポイントが多い場合、特に計算コストは顕著になります。さらに、複雑なモデルを使用すると、計算時間やリソースの要求がさらに増加する可能性があります。
このため、多変量代入法を採用する際には、必要な計算リソースと処理時間を事前に慎重に評価することが重要です。また、計算コストと精度のバランスを考慮し、プロジェクトの要件に合わせて最適な手法を選択することが求められます。
課題2:モデル選択とパラメータの調整
多変量代入法を使用する際、適切なモデルの選択とパラメータの調整は、データの特性と分析の目的に基づいて非常に慎重に行う必要があります。間違ったモデル選択やパラメータの設定は、欠損データの推定精度に悪影響を与え、結果として分析の品質を低下させる可能性があります。
モデル選択においては、データセットの特性(例えば、変数間の相関関係、データの分布の形状、欠損パターンなど)を考慮することが重要です。たとえば、データに線形関係が強い場合は線形回帰モデルが適切であり、非線形関係や複雑なパターンがある場合はより高度なモデルが必要になります。
また、パラメータの調整に関しても同様の注意が必要です。パラメータの選択は、モデルの複雑さ、推定の精度、計算コストのトレードオフを考慮して行う必要があります。適切なパラメータ設定により、モデルはデータの特性をより正確に捉え、信頼性の高い推定値を提供することができます。
モデル選択とパラメータ設定の過程では、しばしば試行錯誤が必要となります。このプロセスは、データの理解を深め、分析の目的に沿った最適な手法を見つける上で不可欠です。
課題3:過剰なデータ補完
多変量代入法、特にMICEのような手法を使用する際には、過剰なデータ補完によって元のデータの特性が歪む可能性があるという課題があります。多変量代入法では、欠損データを補完するために変数間の関係性を用いて推定を行いますが、これが過度に行われると、元のデータセットに存在していた自然な変動やパターンが失われる恐れがあります。
特に、MICEのように反復的な手法を用いる場合、各反復での代入が元のデータの特性を徐々に変化させることがあります。これは、元のデータには存在しない新たなパターンを導入することになり、分析結果の解釈を誤る原因となることがあります。
この問題を避けるためには、データ補完のプロセスにおいて慎重なアプローチが必要です。特に、欠損データのパターンや量を事前に詳細に分析し、必要最小限の補完に留めることが重要です。また、補完されたデータに対する検証作業も不可欠であり、データの分布や統計的特性が元のデータセットと大きく異なっていないかを確認することが必要です。
課題4:データの種類とサイズの制限
多変量代入法は、さまざまなデータセットに適用可能ですが、その効果はデータの種類やサイズによって制限される場合があります。特に、大規模なデータセットや高次元のデータに対しては、いくつかの問題が生じる可能性があります。
- 大規模データセット
データポイントの数が非常に多い場合、多変量代入法の計算コストが顕著に増加します。これは、特に反復的な手法や複雑なモデルを用いる場合に顕著です。大規模データセットにおいては、計算リソースの制約や処理時間の長さが大きな問題となり得ます。
- 高次元のデータ
「次元の呪い」と呼ばれる現象は、特に高次元のデータセットにおいて問題となります。データの次元が増えるにつれて、各変数間の有意な関係を見つけ出すことが難しくなります。これにより、欠損値の適切な推定が困難になることがあり、分析結果の信頼性に影響を及ぼす可能性があります。
- 特定のデータタイプの扱い
一部のデータタイプ、特にカテゴリカルデータや時間系列データなどは、多変量代入法を適用する際に特別な考慮が必要です。これらのデータタイプは、特有の特性を持っており、一般的な手法をそのまま適用することが難しい場合があります。
これらの問題を克服するためには、データの前処理、適切な手法の選択、計算リソースの管理などに特別な注意を払う必要があります。また、データセットの特性に応じたカスタマイズされたアプローチを採用することが、これらの課題を解決する鍵となります。
6. 多変量代入法の実用例
多変量代入法は、様々な分野で実用的な応用を見せています。
- 医療データの分析: 医療分野のデータセットでは、しばしば患者の記録からの欠損データが発生します。多変量代入法を用いることで、患者の他の健康指標や履歴に基づいて欠損値を推定し、より正確な臨床研究や治療計画を立てることが可能になります。
- 市場調査: 消費者調査や市場分析では、回答者の一部から回答を得られないことがあります。多変量代入法を使用することで、既存のデータから欠損値を補完し、より正確な市場傾向の分析や消費者行動の予測を行うことができます。
ケース1:医療データの分析
医療分野では、患者の記録からの欠損データは一般的な問題です。これは、患者が特定のテストを受けていない、あるいは記録が不完全であるなどの理由によるものです。このような場合、多変量代入法を用いることで、患者の他の健康指標や医療履歴に基づいて欠損値を推定し、データセットを補完することが可能になります。このアプローチにより、研究者や医師はより完全で正確なデータに基づいて臨床研究を行うことができます。
例えば、患者の過去の診断記録、治療履歴、生活習慣などの情報を組み合わせることで、欠損している血液検査の値を推定できます。これにより、特定の疾患のリスク評価や治療計画の策定において、より精確な判断を下すことが可能になります。
ケース2:市場調査
市場調査や消費者調査では、回答者から完全なデータを得ることが常に可能ではありません。回答者が特定の質問に答えなかったり、調査全体に参加しなかったりするケースがしばしばあります。このような場合、多変量代入法を使用することで、欠損値を効果的に補完し、より包括的で信頼性の高い市場分析を行うことが可能になります。
多変量代入法は、既存のデータから欠損値を推定するために、回答者の他の回答や属性情報を利用します。例えば、消費者の年齢、性別、過去の購買履歴などの情報を用いて、特定の商品に対する意向や好みを推定することができます。これにより、市場の傾向分析、消費者行動の予測、製品開発やマーケティング戦略の策定において、より正確な情報に基づく意思決定が可能になります。
多変量代入法を用いることで、不完全なデータからも有用な洞察を引き出し、市場の動向をより正確に理解することが可能になるのです。
7. 実用上、検討すべきこと
多変量代入法は、様々な分野で実用的な応用を見せていますが、同時にその適用には壁や限界も存在します。そのため、実務で使うときに幾つかの検討すべきことがあります。以下の3つの検討すべことを、お話しします。
- データの質と完全性: 多変量代入法は、元のデータに十分な情報が含まれている場合に最も効果的です。データが極端に不均衡であったり、重要な変数が欠けている場合、推定の精度は大きく低下します。
- 複雑な関係性の取り扱い: 変数間に非線形関係や相互依存性が存在する場合、適切なモデルを選択しパラメータを調整することが難しくなります。これにより、正確な欠損値の推定が困難になることがあります。
- 計算資源の制約: 特に大規模データセットや複雑なモデルを用いる場合、計算コストが非常に高くなることがあります。これは、実務環境において大きな制約となることがあります。
検討事項1:データの質と完全性
多変量代入法の有効性は、元のデータセットの質と完全性に大きく依存します。この手法は、データに含まれる情報が豊富でバランスが取れている場合に最も効果的です。一方で、データが極端に不均衡であったり、分析に重要な変数が欠けている場合、欠損値の推定精度は大きく低下する可能性があります。
たとえば、ある変数の欠損データを別の変数の値で補完するには、それらの変数間に有意な相関関係が存在する必要があります。しかし、重要な変数が欠けている場合、残されたデータだけでは十分な情報を提供できず、結果的に不正確な推定を導く可能性があります。また、データが一方に偏っている場合(例えば、ある特定のカテゴリーのデータしかない場合)、これもまた推定のバイアスを生じさせる要因となります。
したがって、多変量代入法を適用する前に、データセットの品質を詳細に評価し、必要に応じてデータの前処理やクレンジングを行うことが重要です。これにより、推定の信頼性と精度を高めることができます。
検討事項2:複雑な関係性の取り扱い
多変量代入法の適用において、変数間の複雑な関係性を適切に扱うことは大きな課題です。特に、データセット内の変数間に非線形関係や強い相互依存性が存在する場合、適切なモデルの選択とパラメータの調整が難しくなります。これにより、正確な欠損値の推定が困難になることがあります。
非線形関係を持つ変数の場合、単純な線形モデルではデータの特性を捉えることができません。このような状況では、より高度な統計モデルや機械学習アルゴリズムが必要となります。しかし、これらの複雑なモデルは、適切な設定や調整が非常に重要であり、さらに計算コストが高くなることがあります。
また、変数間に強い相互依存性がある場合、一つの変数の欠損値を推定することが他の変数の推定に影響を与える可能性があります。このような相互依存性を適切にモデル化することは、多変量代入法において特に重要です。
したがって、多変量代入法を使用する際には、データの特性を深く理解し、適切な統計モデルやアルゴリズムを慎重に選択する必要があります。また、モデルのパラメータを調整し、データの特性に適合させることが、正確な欠損値の推定には不可欠です。
検討事項3:計算資源の制約
多変量代入法を使用する際のもう一つの重要な考慮事項は、計算資源の制約です。特に大規模なデータセットや複雑なモデルを用いる場合、この手法の計算コストは非常に高くなります。これは、特に実務環境において、プロジェクトの実行可能性に影響を与える可能性があります。
多変量代入法、特にMICEのような反復的な手法を用いる場合、各反復での複数の変数に対する計算処理が必要となります。これにより、大量のデータポイントを持つデータセットでは、計算にかかる時間が膨大になる可能性があります。また、より複雑な統計モデルや機械学習アルゴリズムを使用する場合、計算コストはさらに増加します。
これらの計算資源の制約を考慮するためには、計算効率を最適化する戦略が必要です。これには、データのサンプリング、効率的なアルゴリズムの選択、並列計算やクラウドベースの計算リソースの活用などが含まれます。また、計算コストと分析の精度のバランスを適切に取ることが重要です。
多変量代入法は強力なツールですが、その利用は計算資源の可用性と関連しています。したがって、プロジェクトを始める前に、必要な計算資源と時間を慎重に評価し、プロジェクトの目的と制約に合わせて適切な手法を選択することが重要です。
8. 今後の展望
多変量代入法は、欠損データの扱いにおいて重要な役割を果たしていますが、今後の展望にはさらなる進化と応用が期待されます。
(1)テクノロジーの進化と応用
- 高度なアルゴリズムの開発: 現在利用されている多変量代入法は、今後さらに高度なアルゴリズムによって進化する可能性があります。特に、機械学習と人工知能の進歩は、より複雑なデータパターンの識別と効率的な欠損値の推定を可能にします。
- ビッグデータの活用: ビッグデータ技術の発展に伴い、より大規模なデータセットでの多変量代入法の利用が可能になります。これにより、より複雑で多様なデータソースからの洞察を得ることができ、精度の高い分析が実現します。
- リアルタイム処理の実現: 計算能力の向上により、リアルタイムまたはほぼリアルタイムでのデータ処理が可能になることで、迅速な意思決定や予測が実現します。
(2)応用分野の拡大
- 様々な産業への応用: 既に医療、金融、市場調査などの分野で用いられている多変量代入法は、教育、製造業、物流など、さらに多くの産業に応用される可能性があります。
- 複雑な問題への対応: 変化する市場の動向、気候変動などの複雑な問題に対して、多変量代入法を用いたデータ分析が、より深い洞察を提供する手段となります。
- 個人化とカスタマイズ: データ分析の個人化が進むにつれて、多変量代入法はよりカスタマイズされたアプローチを提供することが可能になります。個々のユーザーの行動パターンや嗜好に基づくデータを分析することで、個人化されたサービスや製品の提供が可能になります。
(3)メソドロジーの進化
- 統合的なデータ処理手法の発展: 多変量代入法は、他のデータ処理手法や分析技術と組み合わせることで、より強力な分析ツールとなる可能性を秘めています。たとえば、予測モデリング、時系列分析、因果関係の分析などと組み合わせることで、データからの洞察を深めることができます。
- ユーザーフレンドリーなツールの開発: 多変量代入法の複雑さを軽減し、より広範なユーザーが容易にアクセスできるような、直感的でユーザーフレンドリーなツールの開発が進むでしょう。
- 教育とトレーニング: データ科学の教育とトレーニングプログラムにおいて、多変量代入法のような高度な手法の教育が強化されることで、より多くのデータサイエンティストがこの手法を効果的に活用できるようになります。
多変量代入法は、データ分析の分野で重要な位置を占めており、その進化と応用は今後も続くでしょう。テクノロジーの進歩と応用分野の拡大により、この手法はさらに多様なデータセットに対応し、より正確で洞察に満ちた分析を提供することが期待されます。また、メソドロジーの進化とツールの開発により、多変量代入法はよりアクセスしやすく、効果的なデータ分析手法となるでしょう。
次回に続きます。
◆関連解説記事:データサイエンスとは?データサイエンティストの役割は?必要なツールも紹介
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!