▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
▼さらに幅広く学ぶなら!
「分野別のカリキュラム」に関するオンデマンドセミナーはこちら!
データドリブンな意思決定がビジネスの成功に不可欠となる現代において、コスト感応学習は企業が直面する複雑な課題に対処するための鍵となります。このアプローチを通じて、企業はリスクとコストを精密に評価し、最適化された戦略を立てることが可能になります。今回は、ファイナンスからヘルスケア、マーケティング、サプライチェーン管理に至るまで、さまざまな業界でのコスト感応学習の具体的な活用事例を紹介します。また、ビジネス実装の課題、そして将来展望についても言及し、ビジネスリーダーがこの重要なツールをどのように活用していけばよいかの洞察を提供します。コスト感応学習は、より正確な意思決定を促進し、リソースの最適化、リスク管理の強化、そして最終的には収益性の向上を実現するための、今日のビジネスに欠かせないアプローチです。
【記事要約】
コスト感応学習は、不均衡データにおける意思決定の精度を高め、ビジネスプロセスを最適化するための強力な手法です。幾つかの業界にわたるコスト感応学習の応用事例を紹介し、その実装における課題を説明します。さらに、技術の進化、応用分野の拡大、ビジネスモデルへの影響といった将来展望を通じて、このアプローチがビジネスと社会に与える長期的な影響のお話しをします。コスト感応学習のさらなる研究と開発は、データの価値を最大限に活用し、より効率的で公正な意思決定プロセスを実現するために不可欠です。このアプローチを適切に活用することで、企業はリスクを効果的に管理し、競争力を高め、持続可能な成長を達成することができるでしょう。
1. はじめに
(1)不均衡データとは何か、ビジネスにおけるその影響
不均衡データは、一部のクラスやカテゴリーが他のものに比べて圧倒的に多い、または少ない状態を指します。ビジネスの世界では、このようなデータは日常的に遭遇します。例えば、詐欺検出では正規の取引が詐欺取引に比べて遥かに多く、顧客離反分析ではほとんどの顧客がブランドに忠実であるなどです。これらの不均衡は、モデルが多数クラスを過剰に学習し、少数クラスを見過ごす原因となり、ビジネス上重要な洞察の損失や誤った意思決定に繋がります。
(2)コスト感応学習の概要と、不均衡データ問題解決へのアプローチ
コスト感応学習は、この不均衡データ問題に対処するための有効な手段です。このアプローチでは、すべての誤分類が同じ影響を持つわけではないという事実に着目します。特定の誤分類がビジネスに与える損害は、その性質や発生頻度によって大きく異なることがあります。コスト感応学習を通じて、これらの異なるコストをモデルの学習プロセスに組み込むことで、少数クラスの重要な事例を見逃さず、全体としてよりバランスの取れた予測を行うことが可能になります。
2. コスト感応学習の基本
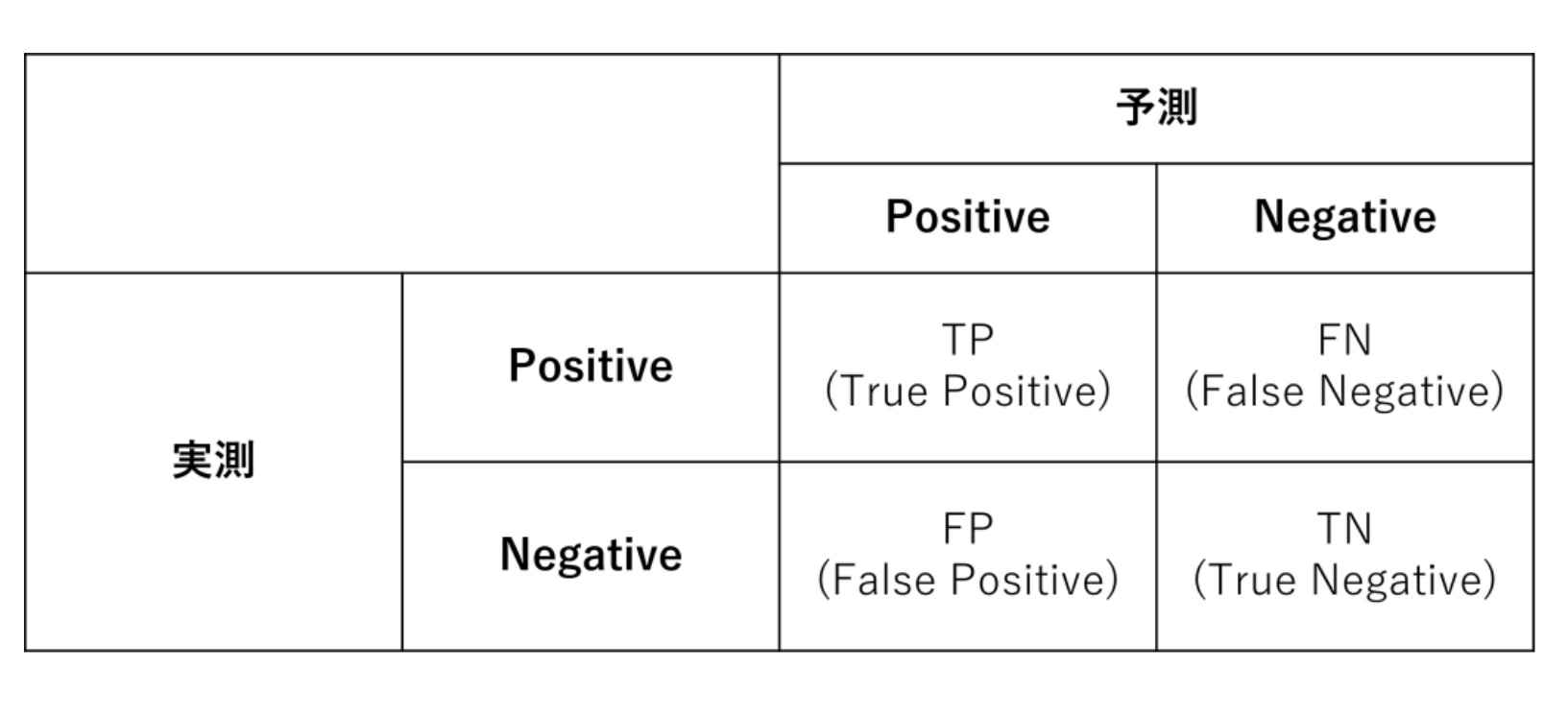
(1)コスト感応学習の原理とメカニズム
コスト感応学習は、異なるタイプの誤分類が異なるコスト(影響)を持つという考えに基づいています。標準的な機械学習モデルは、すべての誤分類を同等に扱いますが、コスト感応学習では、誤分類の種類に応じて重み付けを行い、モデルが最も重要なケースの正確な分類に焦点を当てるようにします。これは、特にビジネスの文脈で、一部の誤りが他のものよりもはるかに重大...
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
▼さらに幅広く学ぶなら!
「分野別のカリキュラム」に関するオンデマンドセミナーはこちら!
データドリブンな意思決定がビジネスの成功に不可欠となる現代において、コスト感応学習は企業が直面する複雑な課題に対処するための鍵となります。このアプローチを通じて、企業はリスクとコストを精密に評価し、最適化された戦略を立てることが可能になります。今回は、ファイナンスからヘルスケア、マーケティング、サプライチェーン管理に至るまで、さまざまな業界でのコスト感応学習の具体的な活用事例を紹介します。また、ビジネス実装の課題、そして将来展望についても言及し、ビジネスリーダーがこの重要なツールをどのように活用していけばよいかの洞察を提供します。コスト感応学習は、より正確な意思決定を促進し、リソースの最適化、リスク管理の強化、そして最終的には収益性の向上を実現するための、今日のビジネスに欠かせないアプローチです。
【記事要約】
コスト感応学習は、不均衡データにおける意思決定の精度を高め、ビジネスプロセスを最適化するための強力な手法です。幾つかの業界にわたるコスト感応学習の応用事例を紹介し、その実装における課題を説明します。さらに、技術の進化、応用分野の拡大、ビジネスモデルへの影響といった将来展望を通じて、このアプローチがビジネスと社会に与える長期的な影響のお話しをします。コスト感応学習のさらなる研究と開発は、データの価値を最大限に活用し、より効率的で公正な意思決定プロセスを実現するために不可欠です。このアプローチを適切に活用することで、企業はリスクを効果的に管理し、競争力を高め、持続可能な成長を達成することができるでしょう。
1. はじめに
(1)不均衡データとは何か、ビジネスにおけるその影響
不均衡データは、一部のクラスやカテゴリーが他のものに比べて圧倒的に多い、または少ない状態を指します。ビジネスの世界では、このようなデータは日常的に遭遇します。例えば、詐欺検出では正規の取引が詐欺取引に比べて遥かに多く、顧客離反分析ではほとんどの顧客がブランドに忠実であるなどです。これらの不均衡は、モデルが多数クラスを過剰に学習し、少数クラスを見過ごす原因となり、ビジネス上重要な洞察の損失や誤った意思決定に繋がります。
(2)コスト感応学習の概要と、不均衡データ問題解決へのアプローチ
コスト感応学習は、この不均衡データ問題に対処するための有効な手段です。このアプローチでは、すべての誤分類が同じ影響を持つわけではないという事実に着目します。特定の誤分類がビジネスに与える損害は、その性質や発生頻度によって大きく異なることがあります。コスト感応学習を通じて、これらの異なるコストをモデルの学習プロセスに組み込むことで、少数クラスの重要な事例を見逃さず、全体としてよりバランスの取れた予測を行うことが可能になります。
2. コスト感応学習の基本
(1)コスト感応学習の原理とメカニズム
コスト感応学習は、異なるタイプの誤分類が異なるコスト(影響)を持つという考えに基づいています。標準的な機械学習モデルは、すべての誤分類を同等に扱いますが、コスト感応学習では、誤分類の種類に応じて重み付けを行い、モデルが最も重要なケースの正確な分類に焦点を当てるようにします。これは、特にビジネスの文脈で、一部の誤りが他のものよりもはるかに重大な結果を招く場合に有効です。コスト感応学習のメカニズムは、学習アルゴリズムの最適化関数を修正して、誤分類に関連するコストを考慮に入れることにより実現されます。つまり、モデルは誤分類を全く避けるのではなく、総コストを最小限に抑えるように学習します。
(2)異なるタイプのコストとそのビジネスへの影響
コスト感応学習における「コスト」もしくは「価値」(コストの減少)は、主に以下の四つのカテゴリに分けて考えていきます。
- 偽陽性(False Positive): 実際には負のクラスに属するが、誤って正のクラスに分類されるケース。ビジネスでの例としては、実際には正当な取引を詐欺と誤認識し、顧客満足度の低下やブランドの信頼性損害を引き起こす場合があります。
- 偽陰性(False Negative): 実際には正のクラスに属するが、誤って負のクラスに分類されるケース。詐欺検出での偽陰性は、詐欺行為を見逃し、企業に直接的な財務損失をもたらす可能性があります。
- 真陽性(True Positive): 正のクラスが正しく識別されるケース。これは、ビジネスのリスクを適切に管理し、潜在的な損失を回避するのに役立ちます。
- 真陰性(True Negative): 負のクラスが正しく識別されるケース。これは、不必要な警告や対策を避け、リソースをより効率的に使用するのに役立ちます。
これらの異なるタイプのコストを理解し、適切にモデルに組み込むことで、ビジネスは不均衡データの課題を乗り越え、リスクを管理しながら最大限のリターンを追求することが可能になります。
(3)偽陽性と偽陰性に対するコスト
偽陽性(False Positive, FP)と偽陰性(False Negative, FN)に対するコストは、モデルの予測が誤っている場合に発生する損失や不利益を指します。これらの誤分類によるコストは、ビジネスの文脈において重要な意思決定やリソース配分に直接的な影響を与えます。以下に、これらのコストについて詳しく説明します。
① 偽陽性(False Positive, FP)のコスト
偽陽性は、実際には負のケースを誤って正として分類したケースです。ビジネスの文脈では、この誤分類により以下のようなコストが発生する可能性があります。
- オペレーショナルコストの増加: 誤ったアラートに対応するための時間やリソースが無駄に消費されます。例えば、正当な取引を詐欺と誤認識した場合、その調査には人的資源が必要となり、その分のコストが発生します。
- 顧客満足度の低下: 特に顧客と直接関わるサービスにおいて、誤った判断による顧客の不便や不信感は、顧客満足度の低下や顧客離反のリスクを高めます。
- ブランドイメージの損傷: 頻繁な誤警報や誤った対応は、企業の信頼性やプロフェッショナリズムに疑問を投げかけ、長期的なブランドイメージの損傷につながることがあります。
② 偽陰性(False Negative, FN)のコスト
偽陰性は、実際には正のケースを誤って負として分類したケースです。このタイプの誤分類が引き起こすコストは、しばしばより直接的で重大です。
- 直接的な損失: 詐欺検出の文脈で見逃された詐欺取引は、企業に直接的な財務損失をもたらします。偽陰性のコストは、その取引によって失われた金額や、損害の修復に必要なコストに等しいです。
- リスクと安全性の問題: ヘルスケアにおいては、病気の誤ったネガティブ診断(偽陰性)は、適切な治療の遅れによる健康リスクの増大や、最悪の場合、患者の生命を脅かす結果を招くことがあります。
- 法的責任と罰金: 特定の業界では、規制遵守に関連する事項を見逃すことが法的な問題や罰金を引き起こす原因となることがあります。
(4)真陽性と真陰性に対する価値
真陽性(True Positive, TP)と真陰性(True Negative, TN)に対する「コスト」という表現は、一般的なコスト感応学習の文脈では少し誤解を招くかもしれません。これらの用語は、実際にはモデルの予測が正しい場合に関連する「利益」や「価値」を指し、直接的なコストというよりは、間接的な経済的利益や避けられた損失を意味します。以下に、これらの概念を説明します。
① 真陽性(True Positive, TP)の価値
真陽性は、モデルが正のケースを正しく識別したケースです。この場合の「コスト」という言葉は、実際にはその予測によってもたらされる利益や節約されるコストを指します。例えば、詐欺検出システムで詐欺取引を正しく識別した場合、その「コスト」は実際には詐欺によって発生する可能性のある損失を避けることによる経済的利益です。真陽性の価値は、避けられた損害額、顧客との信頼関係の維持、企業の評判保護など、直接的および間接的な利益として表現されます。
②真陰性(True Negative, TN)の価値
真陰性は、モデルが負のケースを正しく識別したケースです。この場合、不要な介入や調査、処理を避けることができるため、リソースの節約や効率化がもたらされます。例えば、正当な取引を正しく識別し、誤って詐欺とマークすることなく処理することは、顧客満足度を損なうことなく、運用コストを削減します。真陰性の価値は、無駄な処理コストの削減、顧客体験の向上、オペレーショナルな効率性の向上などとして現れます。
(5)数値例: コスト感応学習の適用
ビジネスシナリオとして、ある企業がクレジットカードの不正使用検出システムを運用している場合を考えます。このシステムは、不正取引を正しく識別する(真陽性)、正当な取引を正しく許可する(真陰性)、不正でない取引を誤って不正と判断する(偽陽性)、実際には不正な取引を見逃す(偽陰性)の4つの結果をもたらす可能性があります。
- 年間取引数: 100,000件
- 実際の不正取引率: 1%(1,000件の不正取引)
- 不正取引1件あたりの平均損失: $500
- 偽陽性1件あたりのコスト(顧客不満など): $100
以下は、不正検出モデルのパフォーマンスです。
- 不正取引の検出率(真陽性率): 80%(800件の不正取引を正しく検出)
- 偽陽性率: 2%の正当な取引が誤って不正と判断される(1,980件)
コスト計算をします。
- 真陽性(TP)によるコスト削減:800件の不正取引を正しく検出することで避けられた損失: $500 × 800 = $400,000
- 偽陽性(FP)によるコスト:1,980件の正当な取引を誤って不正と判断したコスト: $100 × 1,980 = $198,000
- 偽陰性(FN)によるコスト:200件の不正取引を見逃したことによる損失: $500 × 200 = $100,000
総コストと利益の評価をします。
- 偽陽性と偽陰性による総コスト: $198,000(FP)+ $100,000(FN)= $298,000
- 真陽性によるコスト削減(避けられた損失): $400,000
この不正検出システムの運用によって、企業は純粋に$400,000 – $298,000 = $102,000のコスト削減(利益)を実現しています。
この数値例は、真陽性と真陰性による利益(この場合は避けられた損失として計算)と、偽陽性および偽陰性によるコストを考慮に入れた場合の、コスト感応学習の効果を示しています。このような分析を通じて、企業はシステムのパフォーマンスを最適化し、総コストを最小化するための戦略を立てることができます。
次回のビジネス効率化の鍵、コスト感応学習: リスクとリターンを見極める(その2):データ分析講座(その362)に続きます。
◆関連解説記事:データサイエンスとは?データサイエンティストの役割は?必要なツールも紹介