【目次】
序論 ←掲載済
第5章 マトリックス・データ(MD)解析法の使い方←今回
第6章 マトリックス図法の使い方
第7章 系統図法の使い方
第8章 アロー・ダイヤグラム法の使い方
第5章 マトリックス・データ(MD)解析法の使い方
5.3 MD解析法について
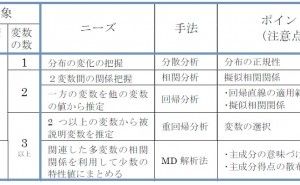
5.3.4 MD解析法のステップの意味と概要
MD解析法の具体的な説明になりますと、どうしても手段であるはずの数理統計学的なことが前面に出てしまうものです。手法の性質上致し方のないことなのですが、難解な数理の理解に注力する余り、手法の持つ本質的なことを見失いがちであったのが筆者の実感です。
その体験から、数式を避け、手法のステップと各ステップの持つ意味を、前節で説明した思考過程に照らして説明し、併せて、心しておくべき活用上の留意点について述べます。次節における事例を用いた詳細説明のガイドとします。
いろいろなステップのとり方があると思いますが、本書では、説明のしやすさから次の14ステップとしました。各統計量がステップごとに順次求められる形にしていますが、これはそれぞれの意味を説明しやすくするためで、実際は解析ソフトにより同時に求められ、たいていのソフトは必要な統計量については2次元座標軸上の散布図表示も同時にアウトプットされるのが普通です。
まず、全貌を把握してもらうために、14のステップと各々のポイントを、若干の説明を付して一覧表にまとめたのが表5-2です。
表5-2 MD解析法による混沌解明のステップとポイント 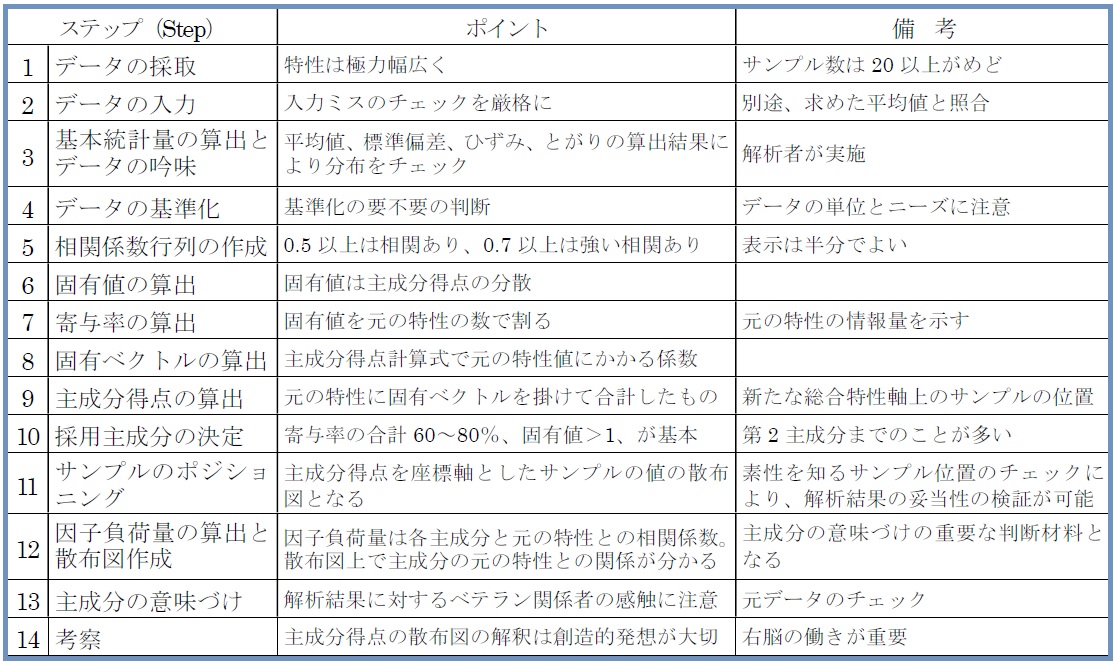
Step 1 : データの採取
解析対象である“混沌C”の性質上、既存の「特性(変数)×サンプル」のマトリックス・データからスタートせざるを得ないケースが多いが、次の点がポイントです。
【ポイント1】特性は極力幅広く採用する
見通しが立っていないための混沌なので、先入観による特性の除外は避け、むしろ気になる特性があれば採用しておきます。これは、親和図法の“一匹狼”への対処に似ており、後で思いがけない効用を発揮することがあります。
【ポイント2】サンプル数は20以上がめど
サンプル数は母集団の推定精度と経済性の兼ね合いで決まりますが、めどとしては、推定精度をサンプル数の大きさに頼る“大標本法”と、少ないサンプルでt変数を用いて推定する“小標本法”との誤差がほとんど無視できるサンプル数といわれる20以上でしょう(ただし、変数の数を下回ったのでは解析の意味がない)。
ただ、「多変量解析法」(奥野忠一他著、日科技連出版、P.220)にサンプル数50のモデル実験結果が出ていますが、大筋で傾向は変わらないものの、各統計量は真の値とかなり違っています。既存データを使う場合、サンプル数は自由にならないことが多いだけに、解析結果の判断時、サンプル数が50くらいあってもこの程度であるということを念頭に判断する必要があります。
Step 2 : データの入力
すべての起点ゆえ、入力ミスに最大限の注意を払うことはもちろんですが、入手したデータの背景などデータそのものに対するチェックもしかるべき人の手で行う必要があります。
【ポイント1】入力は平均値の照合でチェックする
入力ミスのチェックは、変数ごとの平均値を原本のデータを使って別途求めた値と照合するのが効率良く確実です。
【ポイント2】既存データの場合は、採取背景...



















-守・破・離ー")






