企業内のデータサイエンス組織の1つの役割として、データサイエンス技術を、より良い商品の開発やより良いCX(カスタマー・エクスペリエンス)の実現のために用い、ビジネスそのものを成長させる、というものがあります。CX(カスタマー・エクスペリエンス)とは、商品やサービスそのものではなく、購入するまでの過程や使用する過程、購入後のフォローなどの過程における「顧客経験」です。要は、データを活用し、商品そのものと顧客体験をより良いものにする、ということです。今回は、「プロダクトデータサイエンス」の「3つのDS:データサイエンススキル」についてお話しします。
【記事要約】
CX(カスタマー・エクスペリエンス)とは、商品やサービスそのものではなく、購入するまでの過程や使用する過程、購入後のフォローなどの過程における「顧客経験」です。商品開発やCXなどのためにデータサイエンス技術を使い、より良いものにするには、例えばDrew Conway のベン図(2010年に作成され、2013年に一般公開)が参考になります。要は「数学と統計学の知識(Math&Statistics)」がないと、PythonやRなどで高度なデータ分析を実施したところで、その分析結果を正しく解釈することができない、ということです。PythonやR、AutoML、ノーコードツールなどの登場で、手軽にコストをかけずに誰もがデータ分析や数理モデル構築などを実施できるようになりました。しかし、ツールから出力される情報に対する解釈が正しくできているかというと、疑問が拭えません。そこで求められるのが、数学的素養です。
1. 3つのデータサイエンススキル
3つのデータサイエンススキルとは、ハッキングスキル・数学と統計の知識・実質的な専門知識です。
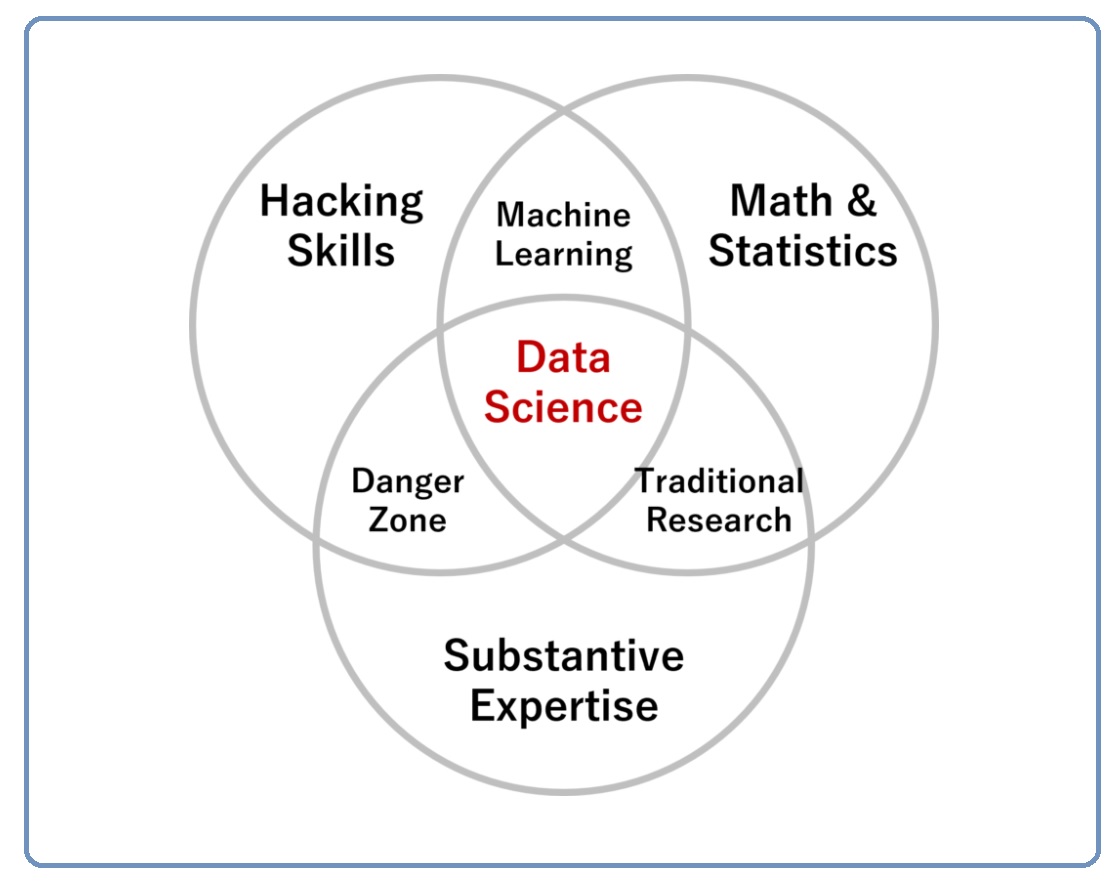
データサイエンススキルを表現するベン図には多くのものがありますが、これはもっとも原始的なもので、Drew Conway のベン図(2010年に作成され、2013年に一般公開)と言われています。ベン図の真ん中に、データサイエンス(Data Science)があります。データサイエンスを実施するには「ハッキングスキル(Hacking Skills)」「数学と統計学の知識(Math&Statistics)」「実質的な専門知識(Substantive Expertise)」を併せ持つことが求められます。
ハッキングスキル(Hacking Skills)とは、簡単に言うとツールを使ったデータに対するハッキングスキルのことです。例えば、PythonやR、SQLなどを自在に操り、データエンジニアリング、集計、変換、数理モデル構築などを行うイメージです。実質的な専門知識(Substantive Expertise)とは、データ活用の対象分野で、プロダクト・データサイエンスという観点でいうと、商品開発やCXなどに関する業務などです。
2. 危険ゾーン(Danger Zone)とは
ハッキングスキル(Hacking Skills)と実質的な専門知識(Substantive Expertise)が重なるところに、危険ゾーン(Danger Zone)があります。
何が危険かというと、分析方法を全く理解しなくてもデータ分析をやった気分になる、分析結果を受けたった側ももっともらしい何かを手に入れた気分になる、などといった危険です。Drew Conway は、回帰分析の例を出していました。「数学と統計学の知識(Math&Statistics)」がないため、分析ツールを使い回帰係数を出力できても、その係数が何を意味するのか理解できていない、というものです。
要は、「数学と統計学の知識(Math&Statistics)」がないと、PythonやRなどで高度なデータ分析を実施したところで、その結果を正しく解釈することができないため、とっても危険だよ! ということです。そのことが、多くの人を危険にさらすかもしれませんし、データサイエンスや機械学習などの不信感にもつながります。
3. データから抽出した情報を正しくドメインに橋渡しする
データサイエンティストと呼ばれる人の多くは、飛び抜けたハッキングスキル(Hacking Skills)と、深い実質的な専門知識(Substantive Expertise)を併せ持っていません。どちらか一方というのはあるかもしれませんが、それはどちらかのバックグラウンドを持った人がデータサイエンティストになった場合です。
コンピュータおたくがデータサイエンティストになる、特定のドメインの専門性の高い人がデータサイエンスのスキルを身に着ける、といったものです。要は、どっちつかず、と感じるかもしれません。どっちつかずでも問題はありません。その代わり必要となるのが、「数学と統計学の知識(Math&Statistics)」です。
そのことで、データから抽出した情報(インテリジェンス)を正しくドメインに橋渡しすることができます。
4. 数学的素養が足りないために間違った解釈をする
PythonやR、AutoML、ノーコードツールなどの登場で、手軽にコストをかけずに誰もがデータ分析や数理モデル構築などを実施できるようになりました。手軽いコストをかけずにツールから出力される情報に対し、解釈が正しくできているかというと疑問が拭えません。
PCの得意な若手にデータ分析をさせ、その結果をもとに業務のベテランと一緒に考える。でも、ちょっとした数学的素養が足りないために、間違った解釈をしてしまう。恐ろしいことです。高度な数学を習得する必要はありません。ただ、最低限の数学的素養がないと、例えば回帰分析で出力される回帰係数の解釈すらままならないことでしょう。
平均値すら適切に...