
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
データサイエンスの進展に伴い、特徴量選択(説明変数の選択)の重要性がますます高まっています。今回は、特徴量選択の基本概念から、PCA(主成分分析)との違い、さらには実践的な特徴量選択手法までをお話しします。特徴量選択がどのようにしてモデルの精度を高め、解釈性を向上させるか、そしてビジネス上の意思決定にどのように貢献するか。データサイエンスを活用するすべてのプロフェッショナルにとって、特徴量選択の知識は非常に重要です。
【記事要約】
データサイエンスにおける一般的な誤解の一つに、「主成分分析(PCA)は特徴量選択手法である」というものがあります。PCAは、多変量データの主要なパターンを把握するための技術であり、特に次元削減に用いられます。次元削減であって、特徴量選択ではありません。特徴量選択: 特徴量選択は、データセットから最も有用な特徴量を選び出し、不要な特徴量を取り除くプロセスです。これにより、モデルのパフォーマンスを向上させ、計算コストを削減し、モデルの解釈性を高めることができます。PCAなどの次元削減: 次元削減は、データセットの特徴量の数を減らし、データの構造をよりシンプルな形にするプロセスです。新しい特徴量空間を作成し、データの圧縮を目的としています。では、特徴量選択手法にはどのようなものがあるのか?主なものに、Recursive Feature Elimination、LASSO、木ベース手法、順列特徴量重要度、ノイズ特徴量の導入という手法があります。これらの手法を適切に活用することで、データからのインサイトを最大化し、より良いビジネス上の決定を下すことができます。特徴量選択は、データサイエンスの世界における中心的なスキルであり、その実践はどのプロジェクトにも不可欠な要素です。
1. データサイエンスにおける特徴量選択の重要性
データサイエンスの世界では、正確で効果的なモデルを構築するためには、適切な特徴量(説明変数)を選択することが不可欠です。このプロセスを「特徴量選択」と呼びます。
(1)特徴量選択とは何か?
特徴量選択とは、モデリングにおいて使用するデータの説明変数(特徴量)を選ぶプロセスです。これには、データセットから最も関連性の高い、または予測力のある特徴量を選択し、余分で無関係、または冗長な特徴量を排除する作業が含まれます。
(2)特徴量選択の目的とメリット
特徴量選択の主な目的は、モデルのパフォーマンスを最適化し、モデルの解釈を容易にすることです。このプロセスには、以下のようなメリットがあります。
- モデルの精度向上・・・不要な特徴量を取り除くことで、ノイズが減り、モデルの精度が向上します。
- 計算効率の向上・・・余分な特徴量を削除することで、訓練時間が短縮され、計算リソースの使用が最適化されます。
- モデルの解釈性の向上・・・主要な特徴量のみを使用することで、モデルの決定プロセスがより透明になり、理解しやすくなります。
特徴量選択は、データサイエンスにおいて非常に重要なステップであり、高品質なモデル構築には欠かせません。
2. 特徴量選択手法というPCA(主成分分析)の誤解
データサイエンスにおける一般的な誤解の一つに、「主成分分析(PCA)は特徴量選択手法である」というものがあります。しかし、これは正確ではありません。
(1)PCAの概要と基本原理
PCAは、多変量データの主要なパターンを把握するための技術であり、特に次元削減に用いられます。次元削減であって、特徴量選択ではありません。PCAでは、元の特徴量から新しい特徴量セット(主成分)を作成します。これらの主成分は、データの最大の分散を捉えるように設計されており、互いに直交(独立)しています。新しい特徴量セット(主成分)が、元の特徴量よりも、その変数の数が少ないというものです。
(2)PCAが特徴量選択と異なる点
PCAは、データの次元を削減し、解析を容易にするための強力なツールですが、特徴量選択の目的には適していません。
- データの変換・・・PCAは元の特徴量を新しい次元に変換しますが、特徴量選択は元の特徴量をそのまま使用します。
- 解釈の難しさ・・・PCAによって生成された主成分は、元の特徴量の組み合わせであり、それらの個別の意味を失います。これに対し、特徴量選択はモデルの解釈を容易にします。
- 全特徴量の利用・・・PCAはすべての元の特徴量を使用して主成分を生成しますが、特徴量選択は不要な特徴量を排除します。
PCAはデータの圧縮や可視化に有用ですが、特徴量の選択やモデルの解釈性向上には貢献しないということを理解することが重要です。
3. 特徴量選択と次元削減の違い
データサイエンスにおいて、特徴量選択と次元削減はよく混同される概念です。以下は、「特徴量選択」と「次元削減」の違いをまとめた表です。

このことを踏まえ、特定のデータサイエンスの問題に対して最適なアプローチを選択することができます。
4. 特徴量選択の実践的な手法
特徴量選択は、モデルのパフォーマンスを向上させ、解釈性を高めるために重要です。特徴量選択に用いられるいくつかの実践的な手法について紹介します。
...
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
データサイエンスの進展に伴い、特徴量選択(説明変数の選択)の重要性がますます高まっています。今回は、特徴量選択の基本概念から、PCA(主成分分析)との違い、さらには実践的な特徴量選択手法までをお話しします。特徴量選択がどのようにしてモデルの精度を高め、解釈性を向上させるか、そしてビジネス上の意思決定にどのように貢献するか。データサイエンスを活用するすべてのプロフェッショナルにとって、特徴量選択の知識は非常に重要です。
【記事要約】
データサイエンスにおける一般的な誤解の一つに、「主成分分析(PCA)は特徴量選択手法である」というものがあります。PCAは、多変量データの主要なパターンを把握するための技術であり、特に次元削減に用いられます。次元削減であって、特徴量選択ではありません。特徴量選択: 特徴量選択は、データセットから最も有用な特徴量を選び出し、不要な特徴量を取り除くプロセスです。これにより、モデルのパフォーマンスを向上させ、計算コストを削減し、モデルの解釈性を高めることができます。PCAなどの次元削減: 次元削減は、データセットの特徴量の数を減らし、データの構造をよりシンプルな形にするプロセスです。新しい特徴量空間を作成し、データの圧縮を目的としています。では、特徴量選択手法にはどのようなものがあるのか?主なものに、Recursive Feature Elimination、LASSO、木ベース手法、順列特徴量重要度、ノイズ特徴量の導入という手法があります。これらの手法を適切に活用することで、データからのインサイトを最大化し、より良いビジネス上の決定を下すことができます。特徴量選択は、データサイエンスの世界における中心的なスキルであり、その実践はどのプロジェクトにも不可欠な要素です。
1. データサイエンスにおける特徴量選択の重要性
データサイエンスの世界では、正確で効果的なモデルを構築するためには、適切な特徴量(説明変数)を選択することが不可欠です。このプロセスを「特徴量選択」と呼びます。
(1)特徴量選択とは何か?
特徴量選択とは、モデリングにおいて使用するデータの説明変数(特徴量)を選ぶプロセスです。これには、データセットから最も関連性の高い、または予測力のある特徴量を選択し、余分で無関係、または冗長な特徴量を排除する作業が含まれます。
(2)特徴量選択の目的とメリット
特徴量選択の主な目的は、モデルのパフォーマンスを最適化し、モデルの解釈を容易にすることです。このプロセスには、以下のようなメリットがあります。
- モデルの精度向上・・・不要な特徴量を取り除くことで、ノイズが減り、モデルの精度が向上します。
- 計算効率の向上・・・余分な特徴量を削除することで、訓練時間が短縮され、計算リソースの使用が最適化されます。
- モデルの解釈性の向上・・・主要な特徴量のみを使用することで、モデルの決定プロセスがより透明になり、理解しやすくなります。
特徴量選択は、データサイエンスにおいて非常に重要なステップであり、高品質なモデル構築には欠かせません。
2. 特徴量選択手法というPCA(主成分分析)の誤解
データサイエンスにおける一般的な誤解の一つに、「主成分分析(PCA)は特徴量選択手法である」というものがあります。しかし、これは正確ではありません。
(1)PCAの概要と基本原理
PCAは、多変量データの主要なパターンを把握するための技術であり、特に次元削減に用いられます。次元削減であって、特徴量選択ではありません。PCAでは、元の特徴量から新しい特徴量セット(主成分)を作成します。これらの主成分は、データの最大の分散を捉えるように設計されており、互いに直交(独立)しています。新しい特徴量セット(主成分)が、元の特徴量よりも、その変数の数が少ないというものです。
(2)PCAが特徴量選択と異なる点
PCAは、データの次元を削減し、解析を容易にするための強力なツールですが、特徴量選択の目的には適していません。
- データの変換・・・PCAは元の特徴量を新しい次元に変換しますが、特徴量選択は元の特徴量をそのまま使用します。
- 解釈の難しさ・・・PCAによって生成された主成分は、元の特徴量の組み合わせであり、それらの個別の意味を失います。これに対し、特徴量選択はモデルの解釈を容易にします。
- 全特徴量の利用・・・PCAはすべての元の特徴量を使用して主成分を生成しますが、特徴量選択は不要な特徴量を排除します。
PCAはデータの圧縮や可視化に有用ですが、特徴量の選択やモデルの解釈性向上には貢献しないということを理解することが重要です。
3. 特徴量選択と次元削減の違い
データサイエンスにおいて、特徴量選択と次元削減はよく混同される概念です。以下は、「特徴量選択」と「次元削減」の違いをまとめた表です。
このことを踏まえ、特定のデータサイエンスの問題に対して最適なアプローチを選択することができます。
4. 特徴量選択の実践的な手法
特徴量選択は、モデルのパフォーマンスを向上させ、解釈性を高めるために重要です。特徴量選択に用いられるいくつかの実践的な手法について紹介します。
(1)Recursive Feature Elimination (RFE)
Recursive Feature Elimination(RFE)は、特に機械学習モデルにおいて重要度が低いと判断される特徴量を段階的に排除することによって、モデルのパフォーマンスを最適化する手法です。このプロセスを通じて、最も影響力のある特徴量のセットを特定します。
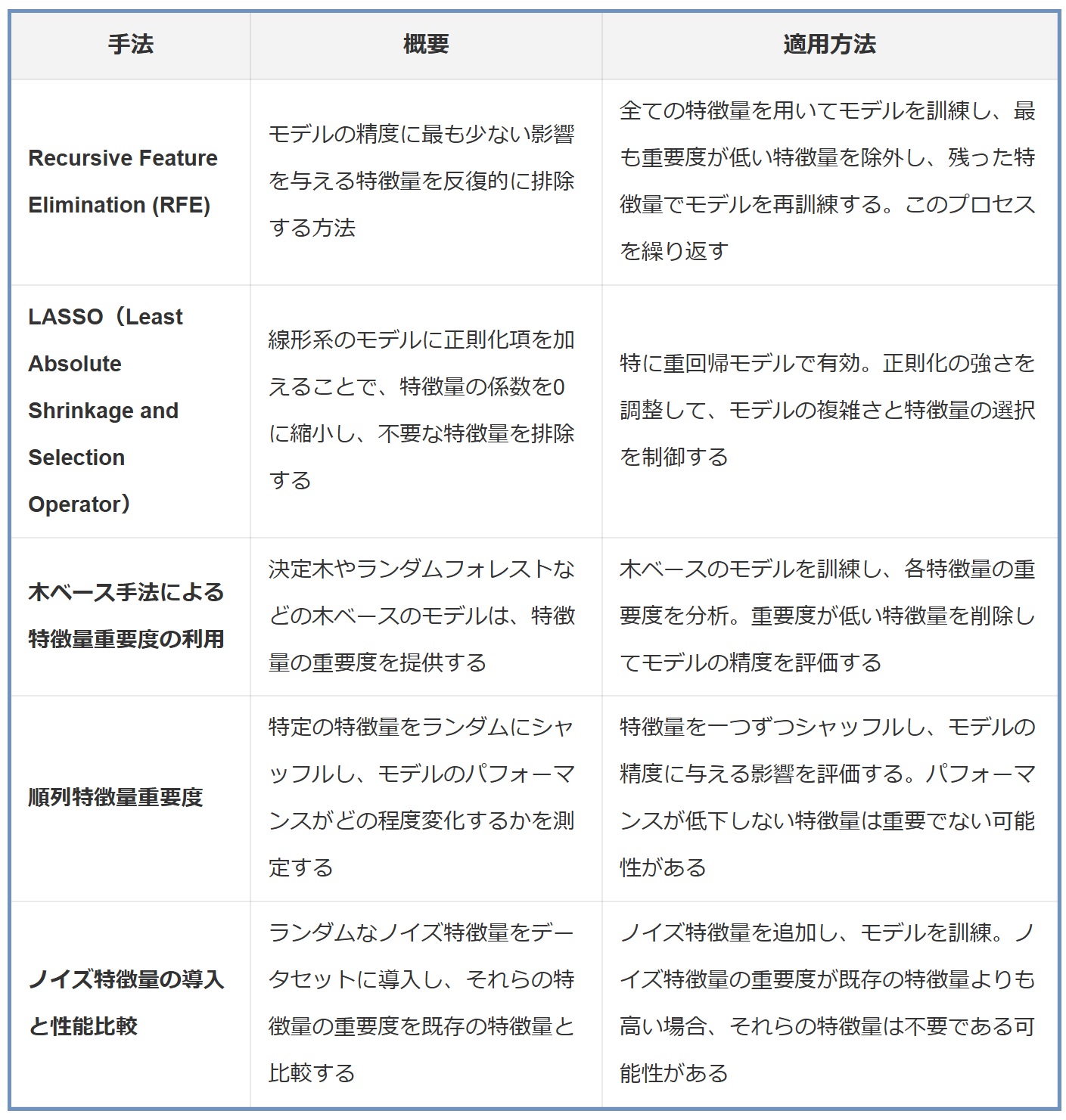
① 適用方法
- モデルの訓練: 最初に、全ての特徴量を用いてモデル(例えば、サポートベクターマシンやロジスティック回帰)を訓練します。
- 特徴量の重要度の評価: 訓練されたモデルから、各特徴量の重要度や係数を評価します。
- 最も重要度が低い特徴量の排除: 最も重要度が低い特徴量(または一定数の特徴量)をデータセットから排除します。
- 再訓練と評価: 残った特徴量を用いてモデルを再訓練し、パフォーマンスを評価します。
- プロセスの繰り返し: 目的の特徴量の数に達するまで、上記のプロセスを繰り返します。
② 適用例
医療データセットで、患者の年齢、性別、体重、血圧、コレステロールレベルなど、複数の特徴量が含まれているとします。
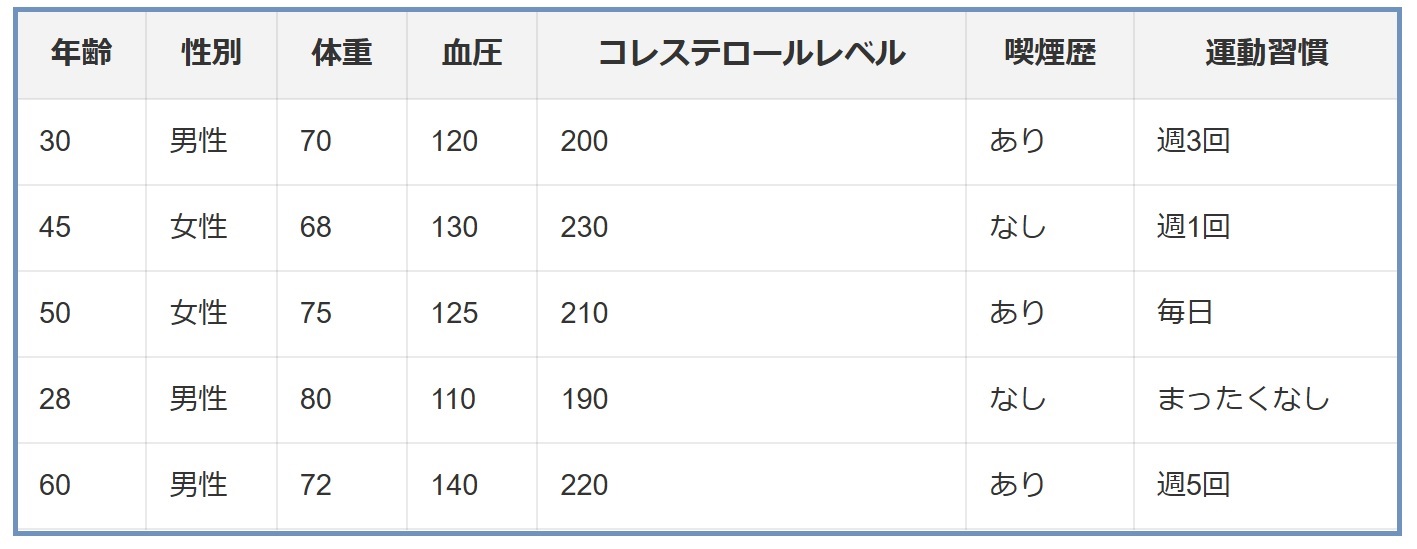
目的は、患者が特定の疾患を発症するリスクを予測することです。
- 初期モデルの訓練: まず、全ての特徴量(年齢、性別、体重など)を用いて、ロジスティック回帰モデルを訓練します。
- 特徴量の重要度評価: このモデルから、各特徴量の係数を評価します。例えば、性別の係数が最も低いと判断されるかもしれません。
- 特徴量の排除: 最も重要度が低い「性別」特徴量をデータセットから排除します。
- モデルの再訓練と評価: 性別を除いた特徴量セットでモデルを再訓練し、そのパフォーマンスを評価します。
- プロセスの繰り返し: 次に重要度が低い特徴量を同様に削除し、再度モデルを訓練します。このプロセスを繰り返し、モデルの精度が大幅に低下しない範囲で特徴量の数を減らしていきます。
このように、RFEはモデルのパフォーマンスに最小限の影響を与えながら、特徴量の数を減らすのに役立ちます。最終的には、予測に最も寄与する重要な特徴量のみが残ります。
(2)LASSO(Least Absolute Shrinkage and Selection Operator)
LASSO(Least Absolute Shrinkage and Selection Operator)は、線形モデルに正則化を導入することで、不要な特徴量の係数を0に縮小し、モデルのパフォーマンスを向上させる手法です。この手法は特に、特徴量が多く互いに相関がある場合に有効です。
① 適用方法
- モデルの設定: LASSOは、通常の線形回帰モデルにL1正則化項を加えたものです。この正則化項は、係数の絶対値の和に基づいています。
- 正則化の強さの調整: LASSOのキーとなるパラメータは正則化の強さ(α)です。αを大きくするほど、より多くの係数が0に縮小されます。
- モデルの訓練と特徴量選択: LASSOモデルを訓練し、係数が0になった特徴量をモデルから除外します。
- モデルの再評価: 削除後の特徴量セットでモデルを再訓練し、パフォーマンスを評価します。
② 適用例
不動産の価格予測データセットで、家の面積、築年数、部屋数、地域、交通の便など、多数の特徴量が含まれているとします。
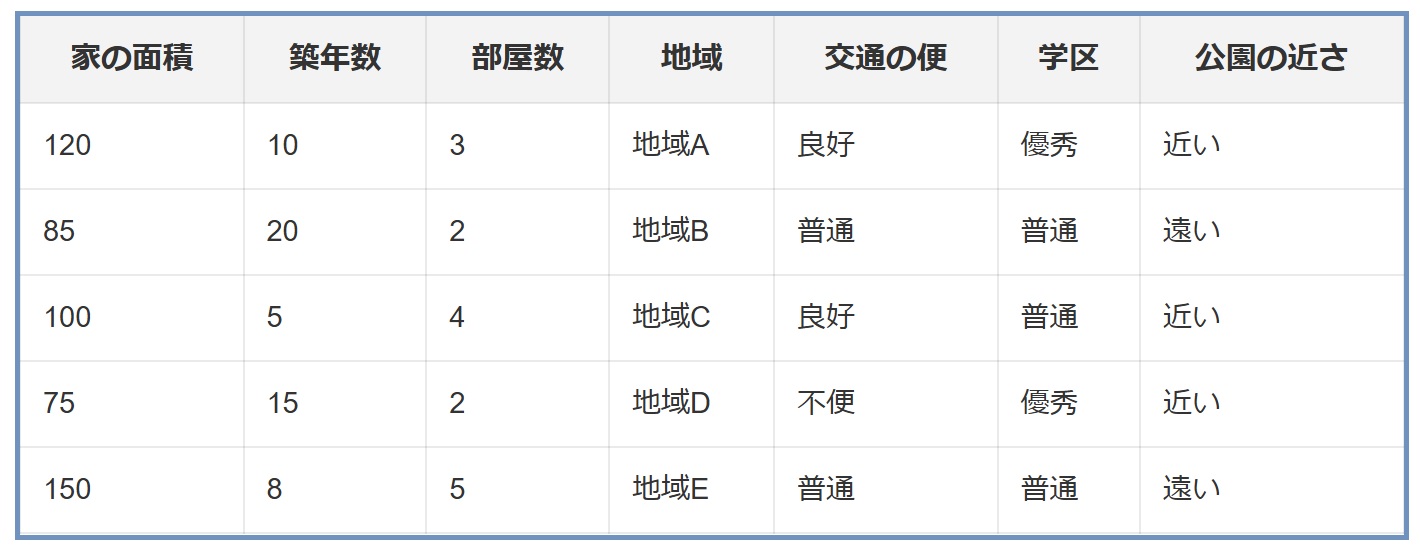
- モデルの設定: まず、LASSOモデルを設定します。このモデルは、家の価格を予測するための線形回帰モデルに、L1正則化項を加えたものです。
- 正則化の強さの調整: αの値を変化させながら、モデルの精度と特徴量の係数を評価します。αが大きいほど、係数が0になる特徴量が増えます。
- 特徴量選択: 訓練したLASSOモデルから、係数が0になった特徴量を特定します。例えば、交通の便の係数が0になった場合、この特徴量は価格予測において重要ではないと判断できます。
- モデルの再評価: 最終的に選ばれた特徴量を用いて、モデルのパフォーマンスを再評価します。
LASSOは、特徴量選択とモデルの正則化を同時に行うことができるため、特に特徴量が多い場合に有効な手法です。適切に正則化パラメータを調整することで、モデルの過学習を防ぎつつ、最も重要な特徴量を特定することができます。
(3)木ベース手法による特徴量重要度の利用
木ベースの手法、特に決定木やランダムフォレストは、特徴量の重要度を理解し、最も影響力のある特徴量を特定するのに非常に有効です。これらのモデルは、各特徴量が予測にどの程度貢献しているかを示す重要度スコアを出力します。
① 適用方法
- モデルの訓練: 木ベースのモデル(例えば、ランダムフォレスト)を訓練します。この際、全ての特徴量を使用します。
- 特徴量重要度の取得: モデルを訓練した後、各特徴量の重要度を取得します。この重要度は、特徴量が分岐の決定にどの程度影響しているかに基づいています。
- 重要度の低い特徴量の削除: 重要度が低いと判断された特徴量を削除します。
- モデルの再評価: 削除後の特徴量セットでモデルを再訓練し、パフォーマンスを評価します。
② 適用例
オンライン小売業の顧客データで、顧客の購入履歴、サイト訪問頻度、年齢、性別、地域などの特徴量が含まれているとします。
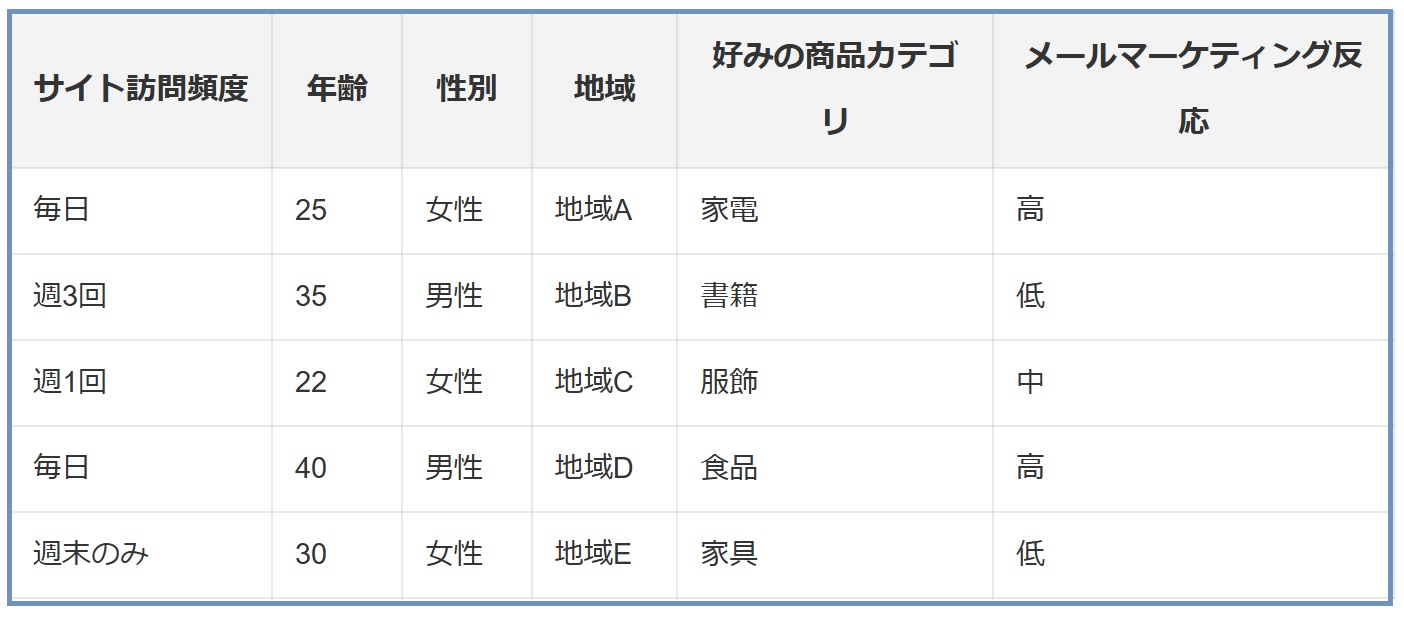
目的は、顧客が将来的に高価な商品を購入するかどうかを予測することです。
- モデルの訓練: まず、ランダムフォレストモデルを全特徴量を用いて訓練します。
- 特徴量重要度の取得: モデルを訓練した後、各特徴量の重要度を取得します。例えば、購入履歴とサイト訪問頻度の重要度が高いと判明するかもしれません。
- 重要度の低い特徴量の削除: 重要度が低いと判断された特徴量(例えば、性別や地域)をデータセットから削除します。
- モデルの再評価: 削除後の特徴量セットでモデルを再訓練し、高価な商品の購入予測精度を再評価します。
このプロセスにより、モデルのパフォーマンスを最適化しつつ、データの解釈性を高めることができます。特徴量の重要度を理解することで、より効果的なデータ駆動型意思決定が可能になります。
(4)順列特徴量重要度
順列特徴量重要度(Permutation Feature Importance)は、特徴量の重要性を評価するために使用される技術です。この方法では、特定の特徴量の値をランダムにシャッフルし、その結果、モデルのパフォーマンスがどの程度変化するかを観察します。パフォーマンスが大幅に低下する場合、その特徴量はモデルにとって重要であると考えられます。
① 適用方法
- モデルの訓練: 最初に、全ての特徴量を使用してモデルを訓練します。
- 特徴量のシャッフル: 一つの特徴量を選び、その値をデータセット内でランダムにシャッフルします。
- パフォーマンスの評価: シャッフル後のデータセットを使用してモデルのパフォーマンスを評価します。
- 重要度の判断: シャッフルによってパフォーマンスが大幅に低下した場合、その特徴量は重要であると判断します。
- 全特徴量の評価: 上記のステップを全特徴量に対して繰り返し、それぞれの重要度を比較します。
② 適用例
クレジットカードの不正使用を検出するためのデータセットで、取引額、取引時間、取引先の地域、カード所有者の年齢などの特徴量が含まれているとします。
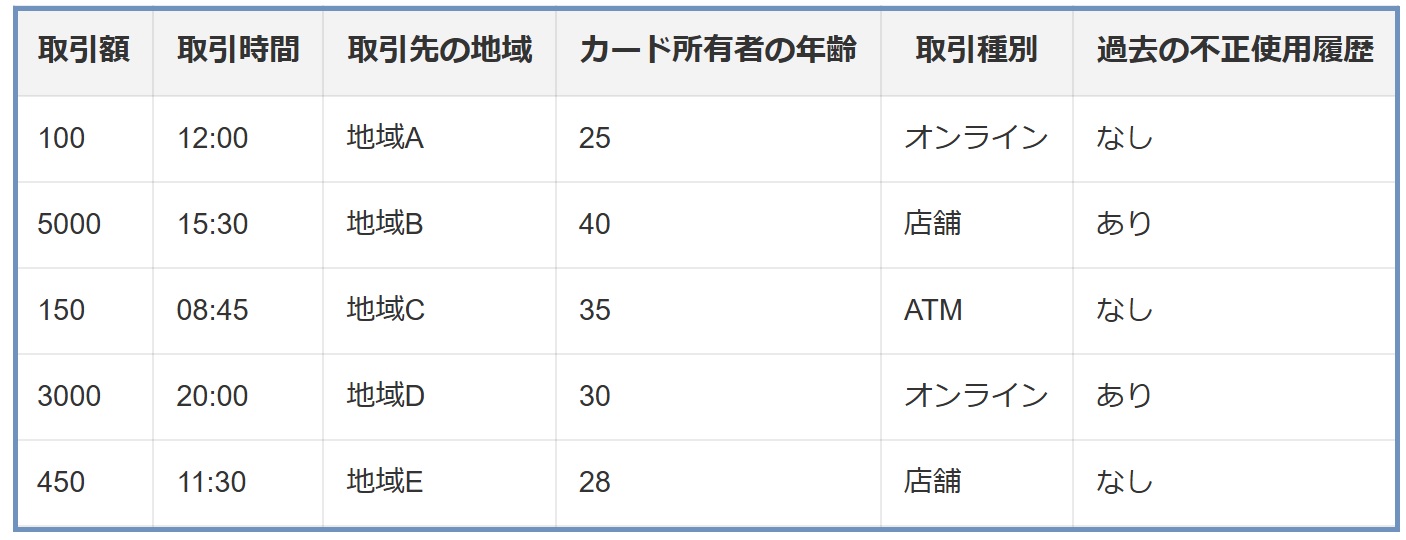
- モデルの訓練: 最初に、全特徴量を用いて不正使用検出モデルを訓練します。
- 特徴量のシャッフル: 「取引額」の値をランダムにシャッフルします。
- パフォーマンスの評価: シャッフルしたデータセットを使用してモデルのパフォーマンスを評価します。
- 重要度の判断: もし「取引額」のシャッフルによって不正使用の検出精度が大幅に低下すれば、取引額は非常に重要な特徴量であると判断できます。
- 他の特徴量の評価: 同様に、他の特徴量(例えば、取引時間やカード所有者の年齢)についてもシャッフルし、その影響を評価します。
この方法により、各特徴量がモデルの予測にどの程度影響を与えているかを客観的に評価することができます。重要度が低いと判断された特徴量は、モデルから除外することを検討できます。
(5)ノイズ特徴量の導入と性能比較
ノイズ特徴量の導入と性能比較は、特徴量選択プロセスにおいてモデルが偶発的なパターンに過度に反応していないかを確認する方法です。この手法では、ランダムなデータ(ノイズ)を新しい特徴量としてデータセットに追加し、これが既存の特徴量と比較してどの程度モデルに影響を与えるかを評価します。
① 適用方法
- モデルの訓練: 最初に、元のデータセットを用いてモデルを訓練します。
- ノイズ特徴量の生成: ランダムな値(ノイズ)から成る新しい特徴量をデータセットに追加します。
- モデルの再訓練と評価: ノイズ特徴量を含む新しいデータセットでモデルを再訓練し、パフォーマンスを評価します。
- 重要度の比較: ノイズ特徴量の重要度を既存の特徴量と比較します。
- 評価と決定: もしノイズ特徴量の重要度が既存の特徴量よりも高い、または同等である場合、それらの既存の特徴量はモデルにとって重要ではない可能性があります。
② 適用例
販売予測モデルのデータセットで、商品の価格、販売日、季節、プロモーションの有無などの特徴量が含まれているとします。
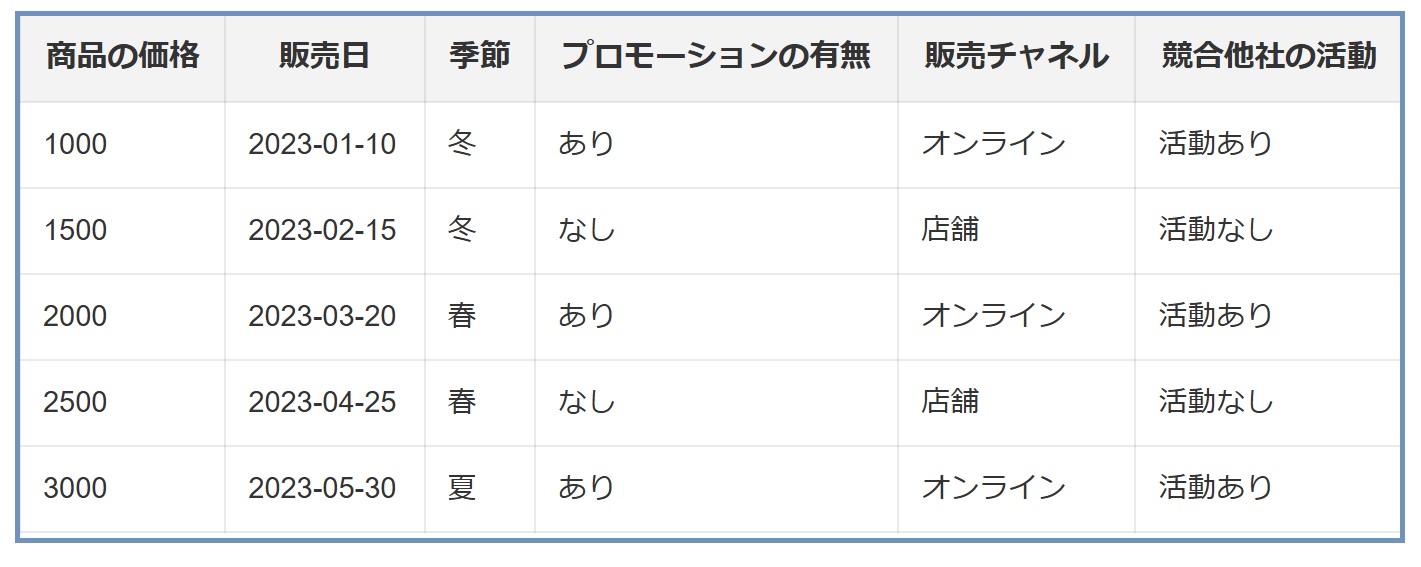
- モデルの訓練: 最初に、既存の特徴量を使用して販売予測モデルを訓練します。
- ノイズ特徴量の生成: ランダムな数値から成るノイズ特徴量をデータセットに追加します。
- モデルの再訓練と評価: ノイズ特徴量を含むデータセットでモデルを再訓練し、そのパフォーマンスを評価します。
- 重要度の比較: ノイズ特徴量の重要度が、例えば「プロモーションの有無」の重要度と同等かそれ以上であれば、この特徴量はモデルにとってそれほど重要ではない可能性があります。
- 評価と決定: この分析を通じて、モデルの予測能力に寄与していない特徴量を特定し、除外することを検討します。
この手法は、モデルが実際の信号ではなくノイズに過剰に反応していないかを確認するのに役立ちます。モデルがランダムなデータに基づいて予測を行っている場合、そのモデルは過学習している可能性があります。
5. 特徴量選択によるデータのエッセンス維持
特徴量選択は、データサイエンスにおける重要なステップです。このプロセスを通じて、データの本質を保ちながら、より効果的かつ解釈可能なモデルを構築することができます。
(1)特徴量選択の最終目標
特徴量選択の目的は、モデルの複雑さを削減し、計算効率を高めると同時に、予測の精度と解釈性を向上させることにあります。適切な特徴量選択により、以下のことが可能になります。
- モデルのパフォーマンスの向上: 不要な特徴量を削除することで、モデルのノイズを減らし、予測精度を向上させます。
- 解釈性の向上: 重要な特徴量のみを使用することで、モデルの背後にある決定ロジックが明確になり、より簡単に解釈できるようになります。
- 計算コストの削減: 余分なデータ処理を避けることで、計算コストと時間を節約できます。
(2)データサイエンスにおける特徴量選択の重要性
特徴量選択は、データサイエンスプロジェクトの成功に不可欠です。データの質と関連性を最大化することで、モデルはより信頼性の高い結果を提供します。また、特徴量選択は、データ解析のプロセスをより透明で理解しやすいものにします。ビジネスの意思決定においては、この透明性と理解のしやすさが特に重要です。Recursive Feature Elimination、LASSO、木ベース手法、順列特徴量重要度、ノイズ特徴量の導入といった特徴量選択の手法は、データサイエンスのプロジェクトにおいて、より効率的で解釈可能なモデルを構築するための強力なツールです。適切な特徴量選択を行うことで、データから最大限の価値を引き出し、ビジネスの成果に貢献することができます。
次回に続きます。
◆関連解説記事:データサイエンスとは?データサイエンティストの役割は?必要なツールも紹介
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!























-その原点を考える")








