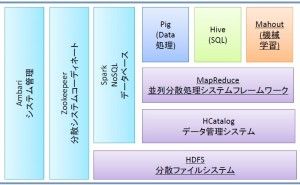
【ビッグデータ処理による機械学習・データマイニング 連載目次】
1. 機械学習とビッグデータの関係性
2. 機械学習法と数理モデリング
3. ビッグデータ処理に対応した機械学習ツール
前回のその1に続いて解説します。
3. 機械学習法と数理モデリング
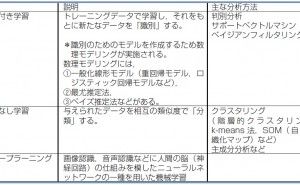
機械学習に関連する用語について表1 に示します。
表1. アルゴリズムによる機械学習の分類とディープラーニング

3.1 教師付き学習と教師なし学習
機械学習は、おおまかに教師付き学習と教師なし学習に分類されます。ひとことでいえば、教師付き学習は「識別」、教師なし学習は「分類」という機能を持っています。詳細を以下に説明します。
(1) 教師付き学習
あらかじめ分類などの情報が紐付け(付与)された入力(数値)データが与えられ、たとえば、患者のデータと健常者のデータ、またはスパムメールかそうでないかなどのデータです。これで、入力データをもとに分類するデータのパターンが学習されます。学習過程が終了したあと、新たなデータが入力されたときに、これがどのカテゴリに属するかを判定します。多変量解析の一種である判別分析・サポートベクトルマシン・ベイジアンフィルタリングなどの方法があります。これらの方法で判別関数のような識別関数が得られます。紐付けデータは、患者か健常者かのような単なるカテゴリー分類だけでなく定量データの場合もあります。定量データが出力データであった場合、線形重回帰分析やロジスティック回帰分析のような数理モデリング(一般化線形モデル)が実施さます。また、最尤(さいゆう)推定法やベイズ推定法など観測データから確率論的に最適な数理モデルを推定する方法もあります。
(2) 教師なし学習
教師なし学習では入力データは、各データの数値とその類似性のみに基づいて分類が行われます。主な分析方法としてデータを分類や分割を行うクラスタリングがあり、階層的クラスタリング、k-means法、自己組織化マップ(SOM)などのクラスタリングの計算方法(アルゴリズム)が知られています。
3.2 予測分析と数理モデリング
教師付き学習において学習モデルを数式化して、入力されるデータに基づき特定事象が起こるかどうかを予測することを予測分析と呼び、臨床診断や株価予測など応用範囲が広いことから注目されています。
3.3 ディープラーニング
この分析手法は、多層化ニューラルネットワークという分析手法を工夫して(スパース・コンピューティング理論と呼ばれる方法により)識別能力を高性能化したものでウェブログ解析などに使われます。
3.4 ベイジアンフィルタリング
データマイニング法のうち最近注目されているベイジアンフィルタリングについて説明します。一般的に確率論的事象が、次のような数式で表現される『ベイズの定理』に従います。
すなわち,A とB という2 つの事象があった場合にそれぞれの事象の起こる確率をP (A)、P (B)とします。P(B|A)は、A が起こった時のB の確率で、P(A|B)は、B が起こった時のAの確率です。たとえば、A :「喫煙習慣のある人」、B:「肺がんになった人」と考えます。この場合、P (B|A)は「喫煙習慣があって肺がんになった人」の割合、P( A|B)は「肺がんになった人のうち喫煙習慣のあった人」の割合です...