【ビッグデータ処理による機械学習・データマイニング 連載目次】
1. 機械学習とビッグデータの関係性
2. 機械学習法と数理モデリング
3. ビッグデータ処理に対応した機械学習ツール
前回のその2に続いて解説します。
4. ビ ッグデータ処理に対応した機械学習ツール
4.1 機械学習用データ分析ツールの概要
データ分析用のツールは、いろいろなものがあります。初心者にとって馴染み深いのは、Excelでしょうか、扱えるデータ量もデータ分析手法も限定されています。商用ソフトとしてはSAS、SPSS などの統計ソフトが考えられますが高価です。オープンソースのソフトウェアでは統計解析ツール:R言語やPython、機械学習用ツールであるWekaなどがよく使用されます。ビッグデータ処理における機械学習システムとしては並列分散処理を用いたHadoop/MapReduceや、その上で動作するMahout、あるいはさらに高速計算が可能なSpark-MLlib があります。
4.2 ビッグデータ処理用プラットフォーム
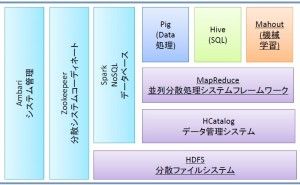
Hadoop/MapReduceおよび機械学習ソフトMahoutデータ分析をする場合、処理するデータのサイズが大きくなって数億行のサイズのデータやテラバイトレベルのファイルを検索するという例も増えてきています。このレベルのサイズを超えるデータをハードディスクに保存する場合は、一個のハードディスクに乗り切らないので、ファイルをバラバラに区切り別々のハードディスクやコンピュータに保存することが行われます。これが「分散ファイルシステム」です。また、コンピュータクラスタ上の複数のコンピュータに並列的に仕事をさせ、これを集計することにより大規模計算を可能にします。これが「並列分散処理」です。このような大規模ビッグデータ処理を可能にした総合フリーソフトがHadoopで、分散ファイルシステムであるHDFSと並列分散処理MapReduceから構成されます(図1参照)このHadoop 上で動作する機械学習システムがMahoutです。これによりビッグデータのレコメンデーションやクラスタリングなどの機械学習が可能になります。
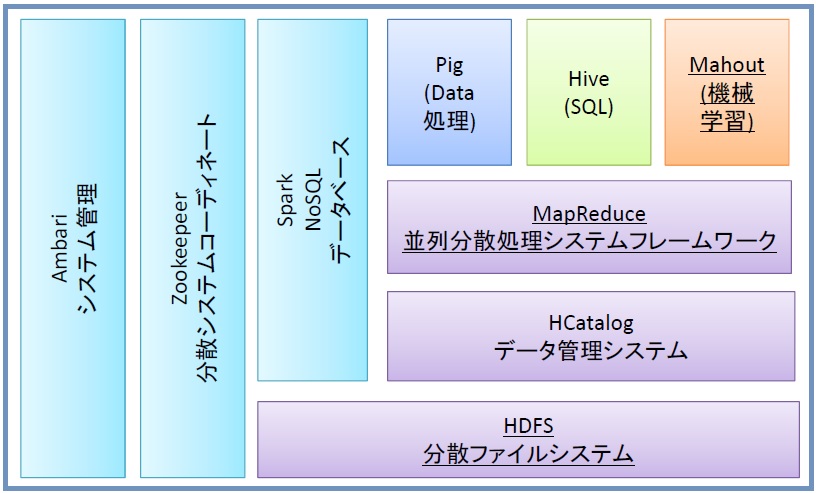
図1. MapReduceおよびMahoutが動作するシステムの構成例
4.3 Spark/MLlib
MapReduceは、ハードディスクレベルで分散処理を行います。それをメモリレベルで分散して計算処理を行うと計算の高速化を図れます。これを実装したものがSpark(Apache Spark)です(図2参照)
図2. Sparkの構成例
すなわち、Sparkはメモリレベルで並列演算処理を実現するインメモリー並列分散化処理を行うためのプラットフォームです。Sparkはメモリレベルでデータを処理するため、ハードディスクレベルでデータを処理するMapReduceより100倍速いといわれています。このSparkで実装された機械学習用ライブラリがMLlibです。MLlibでは、サポートベクトルマシン、ロジスティック回帰分析、線形回帰、k-meansクラスタリングなどができます。Sparkは、2015 年の注目技術として日経BP 社のITインフラテクノロジーAWARD 2015に「準グランプリ」に取り上げられており、現在、急速に普及しています。5)
5. ビッグデータ処理用の機械学習ツール
ビッグデータ処理による機械学習、データマイニングについて、その応用事例に始まり、内容を解説して最新のツールについて述べました。今まさに現在進化中の技術であり最新情報をできる限り掲載することに努めました。問題点としては、Spark-M...




















実践Rケモ・マテリアル・データサイエンス ~ 付録Rスクリプト付き ~")
で学ぶデータサイエンス入門講座")




