◆人工知能の利活用を進めるために
ディープラーニングは、機械学習の手法の一つで、第三次人工知能のブームの牽引車となっています。ディープラーニングの導入により音声や画像の認識率が格段に上がっています。セミナーなどでもディープラーニングの要望は非常に強く感じます。しかし、ディープラーニングは、統計学や従来の機械学習の基盤のうえに成り立つ技術であるので、ディープラーニングのみを学習すれば事足りるというものではありません。きちんと使いこなせるようになるためには、いくつかのステップを踏む必要があります。本稿ではこのようなディープラーニングを身につけるにあたって、なにを学習するか、そのリソースは、という観点から解説します。今回は、その1です。
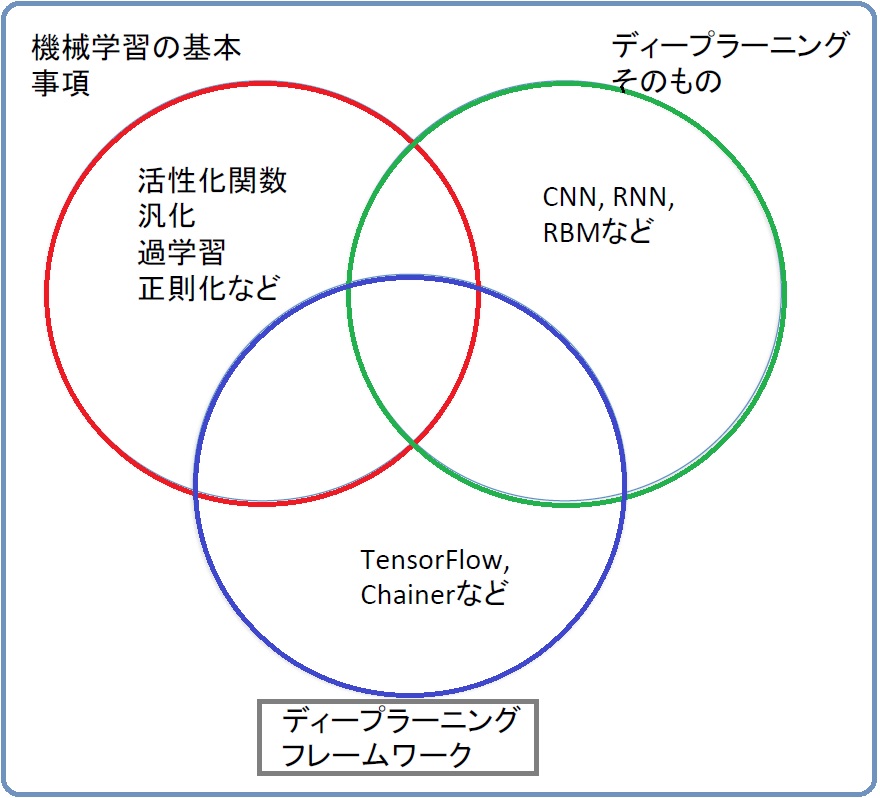
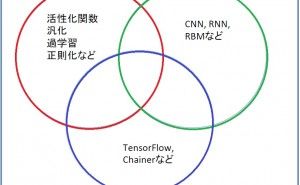
図1. ディープラーニングの学習で押さえておく事項
1. ディープラーニングの基本事項(図1参照)
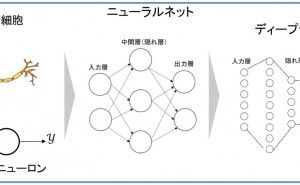
ディープラーニングは、第三次人工知能(AI)ブームの牽引車で、画像分野で精度を上げ、その応用としてグーグルの「AlphaGo」が囲碁の世界王者にも勝利するなど、大きな話題をとなりました。ディープラーニングは、多層型のニューラルネットワークのことです。しかし、その内容は濃縮された内容ですので、それらをきちんと理解する必要があります。注意すべき事項には以下のようなものがあります。
(1) ニューラルネットに関する事項
例えば、ディープラーニングの層を形成する素子(ユニット)には外からの刺激に対して応答する活性化関数というものが存在します。これには、ヘヴィサイドの階段関数やロジスティック(シグモイド)関数が用いられていました。しかし、ディープラーニングではそれではうまくいかず、正規化線形関数(ReLU)が用いられます。これは、重みを求めるための微分計算が容易で、順伝播や逆伝播などで何重にも掛け合わせた結果、重み係数が発散したり、傾きがゼロになったりということを防げることによります。統計的機械学習のモデル関数への当てはめには確率的勾配効果法が用いられます。
(2) 過学習(汎化)の問題
学習過程で教師データに生じる誤差を学習誤差といい、サンプルの母集団に対する誤差の期待値を汎化誤差といいます。学習器の性能評価には汎化誤差を調べることは不可能であるため、テストデータの誤差であるテスト誤差が用いられます。この学習誤差とテスト誤差の乖離を過剰適合(過学習)といいます。過学習を抑える方法には、重み係数に制限を加える正則化や、多層の丹生ラルネットの一部を確率的に選別して使用するドロップアウトなどがあります。そのほかに、データの平均や分散をそろえる正規化や正則化、相関をゼロにする白色化、データのコントラストを変えたりすることで検出精度を上げる工夫がなされます。構造の異なる複数のニューラルネットを組み合わせて汎化性能を上げることも行われます。
2. ディープラーニングのモデルの種類(図1参照)
ニューラルネットワークを多層積み重ねたモデルを機械学習させればディープラーニングとなります。主なディープラーニングのモデルとして以下のものがあります。
(1) 畳み込みニューラルネットワーク(CNN)
全結合していない順伝播型ニューラルネットワークをいくつも重ね合わせた畳み込み層という部分と、それを集約させるプーリング層からなるディープニューラルネットワークです。画像認識に用いられます。
(2) 再帰型ニューラルネットワーク(RNN)
データを数層前にさかのぼって処理するような形式のニューラルネットワークです。動画像、音声、自然言語処理などに用いられます。
(3) 制限付きボルツマンマシン(RBM)
ボルツマンマシンは、各素子が無向グラフとして接続されたネットワークでそれらが層構造になっています。これらのネットワークは有向性でないために計算が困難になりますが、同層の連結を除くことで計算を容易にする制限付きボルツマンマシン(RBM)が開発されています。