テキストマイニングは報告書・議事録・提案書など企業内に散在する日本語情報とネット上のビジネスに有益な情報を自動収集し、日本語解析をかけて整理整頓して、様々な角度から情報を解析・グラフ化するシステムにより業務の品質向上と効率向上がどの程度達成できるかを考察します。今回は企業内およびネット上の大規模データの自動収集および解析システムのビジネスへの応用を解説します。
1、企業内およびネット上の大規模データ
(1) 21世紀の情報利活用
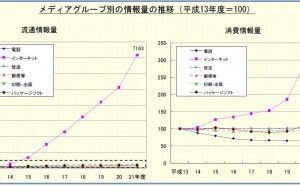
インターネットが社会基盤になり情報量が急速に増加する情報爆発という現象が起こり、今後それがさらに加速することが予測されます。その大量な情報を利活用できるかどうかが競争力を大きく左右する新しい情報利活用ルールの時代となりました。
IDC(Internet Data Center)の予測ではインターネットの情報量は2020年に35ゼタバイトに達するようです。[1]これらの大量のデータは、すでにそのままの形で人間が取り扱うことは不可能なレベルであり 何らかの加工をしてこれら大量のデータを利活用できるようにし、それを企業の競争力に結びつけることが企業の戦略に大きく影響します。
[1]wordpress.digital-universe-iview_5-4-10.pcdofm /2010/05/2010-
http://www.soumu.go.jp/main_content/000124276.pdfより引用。
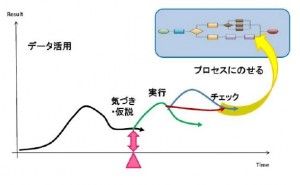
もちろん、情報利活用は目的達成の手段であり目的ではありません。情報利活用の前に目的の明確化が大切であるという原則は変わりません。例えば革新的商品創出のための情報利活用と顧客満足度のための情報利活用はやり方が違うわけです。
(2) 企業が利活用する情報
企業が利活用できる情報のソースは大きく2種類です。一つは社内にあるMicrosoft Office、PDF、テキスト形式などさまざまな形で存在するファイルです。
これらは、メール・議事録・作業日報・営業報告などの作業情報、製品検証レポートの解析・顧客クレームの分析などの解析情報、顧客データ・販売データなどの各種実データといった、社内で時間をかけて作成されたさまざまな情報です。これらの社内情報はデータソースが確認されている確定情報です。しかしながらせっかく多くのリソースをかけて作成されたこれらの確定情報もあまりにも大量にあり、さまざまなシステムに散らばって存在しているため誰にも気づかれずに眠っていることが多いようです。
もう一方がインターネット上に数多(あまた)存在するブログや口コミサイト、Q&am...









![ものづくり現場 AI/DX DAY 2026 summer [for Leaders] 20260729 2days開催](https://assets.monodukuri.com/img/2c84e607-d888-41e6-ba9d-c4046b94052f.png)















