
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
データ不均衡は、医療、金融、ビジネス分析など多くの分野で遭遇する一般的な課題です。稀な事象や少数派のデータを正確に理解し、予測することは、高度なデータ分析スキルを要求されます。今回は、データ不均衡問題に対する効果的な解決策としてのSMOTE(Synthetic Minority Over-sampling Technique)に焦点を当て、その仕組み、適用方法、そしてビジネスへの応用事例を解説します。
【記事要約】
SMOTEの適用により、データ不均衡問題は効果的に解決され、様々な業界でのデータ分析の質が向上します。顧客のチャーン予測、金融詐欺検出、医療診断などの実例を通じて、SMOTEがいかにデータセットのバランスを改善し、より正確で信頼性の高い予測モデルを構築するために貢献するかを見てきました。ただし、SMOTEの適切な使用には、データの特性を理解し、過剰適合やデータの品質を注意深く監視する必要があります。データサイエンスの世界では、SMOTEは強力なツールですが、その使用には洞察と配慮が求められます。
1. データ不均衡の問題とは
データ不均衡は、機械学習やデータ分析でしばしば直面する問題です。この現象は、データセット内の特定のクラス(例えば、’はい‘または’いいえ‘のようなカテゴリ)のサンプル数が他のクラスに比べて極端に少ない場合に発生します。例えば、クレジットカードの不正利用検出のようなケースでは、不正利用の事例は正常なトランザクションに比べて非常に少ないのが一般的です。このような不均衡データが分析やモデルに与える影響は深刻です。不均衡データセットで訓練されたモデルは、多数派クラスに偏った予測をする傾向があり、少数派クラスの重要なパターンや特徴を見逃してしまう可能性が高くなります。これは、特に医療診断、金融詐欺検出、製造業の品質管理など、誤った予測が重大な結果を招く分野で特に問題となります。データ不均衡の問題を理解するために、医療分野における疾患診断の事例を考えてみましょう。ここでは、ある稀ながんの早期発見を目的とした研究を想定します。
- データセットの内容: 10,000人の患者データ
- 目的: このデータを用いてがんの有無を診断するモデルを開発
以下はデータの内訳です。
- がん患者: 100人 (1%)
- がんでない患者: 9900人 (99%)
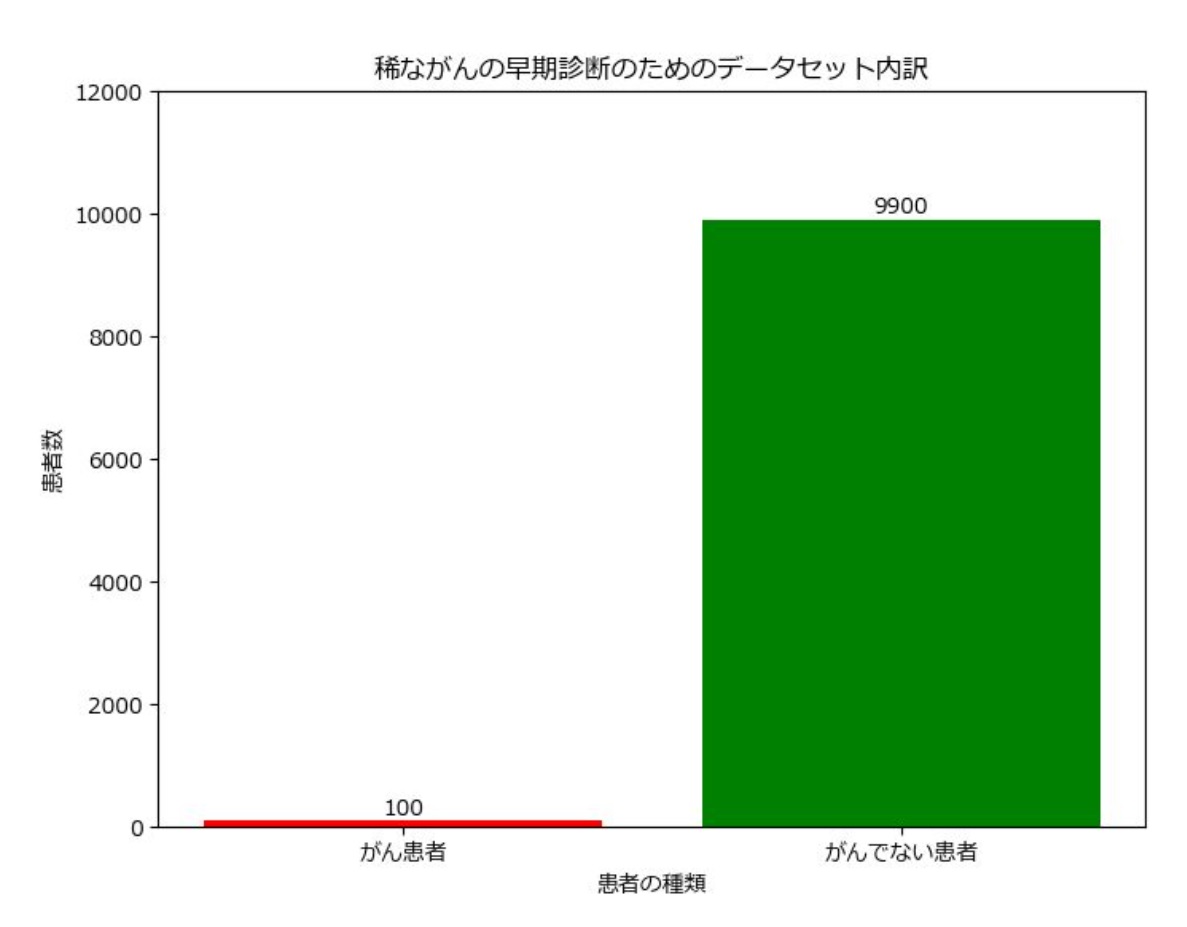
このデータセットでは、がん患者(少数派クラス)とがんでない患者(多数派クラス)の比率が極端に異なります。この不均衡により、モデルはがんでないケースに偏った予測をしてしまいがちです。例えば、すべてのケースで「がんではない」と予測することで高い正答率を示す(正答率99%)ことができますが、その代償として重要な少数派のケース(がん患者)の検出が不可能になります。なぜならば、全てのケースを「がんではない」と予測するからです。このような状況では、モデルががん患者を正しく識別することが極めて重要であり、少数派クラスのサンプルを増やすことが求められます。SMOTEアルゴリズムはこのような場合に有用で、人工的にがん患者のデータを生成してデータセットのバランスを改善することができます。
2. SMOTEアルゴリズムの概要
SMOTE(Synthetic Minority Over-sampling Technique)は、データセットの不均衡を解決するために開発されたアルゴリズムです。この技術は、少数派クラスのサンプルを合成的に増やすことにより、データセットのバランスを改善します。少数派クラスのサンプル数を増やして、データセットのクラス間バランスを改善することで、機械学習モデルは少数派クラスに関するより多くの情報を学習し、その結果、より正確でバランスの取れた予測を行うことができます。SMOTEは、少数派クラスのサンプルから新しいサンプルを合成的に生成しますが、単純なコピーではなく、既存のサンプル間の特徴空間を補間することで、より多様なデータセットを作成します。
3. SMOTEの仕組み
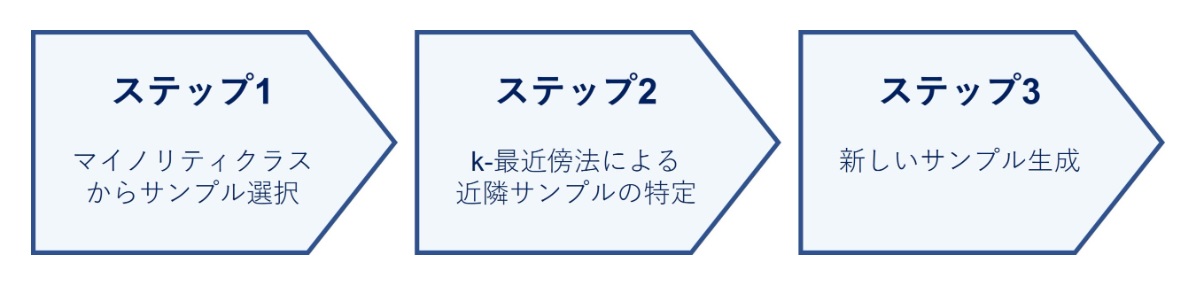
(1)ステップByステップ
SMOTEがどのように機能するのかを具体的なステップに分けて解説します。
ステップ1: マイノリティクラスからサンプル選択
SMOTEはまず、少数派クラス(例えば、がん患者のデータポイント)からランダムにサンプルを選びます。この選択されたサンプルは、新しい合成サンプルを生成する基点となります。
ステップ2: k-最近傍法による近隣サンプルの特定
選択したサンプルのk個の最近傍点(最も近いk個のサンプル)を見つけます。ここでの「最近傍」とは...
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!
データ不均衡は、医療、金融、ビジネス分析など多くの分野で遭遇する一般的な課題です。稀な事象や少数派のデータを正確に理解し、予測することは、高度なデータ分析スキルを要求されます。今回は、データ不均衡問題に対する効果的な解決策としてのSMOTE(Synthetic Minority Over-sampling Technique)に焦点を当て、その仕組み、適用方法、そしてビジネスへの応用事例を解説します。
【記事要約】
SMOTEの適用により、データ不均衡問題は効果的に解決され、様々な業界でのデータ分析の質が向上します。顧客のチャーン予測、金融詐欺検出、医療診断などの実例を通じて、SMOTEがいかにデータセットのバランスを改善し、より正確で信頼性の高い予測モデルを構築するために貢献するかを見てきました。ただし、SMOTEの適切な使用には、データの特性を理解し、過剰適合やデータの品質を注意深く監視する必要があります。データサイエンスの世界では、SMOTEは強力なツールですが、その使用には洞察と配慮が求められます。
1. データ不均衡の問題とは
データ不均衡は、機械学習やデータ分析でしばしば直面する問題です。この現象は、データセット内の特定のクラス(例えば、’はい‘または’いいえ‘のようなカテゴリ)のサンプル数が他のクラスに比べて極端に少ない場合に発生します。例えば、クレジットカードの不正利用検出のようなケースでは、不正利用の事例は正常なトランザクションに比べて非常に少ないのが一般的です。このような不均衡データが分析やモデルに与える影響は深刻です。不均衡データセットで訓練されたモデルは、多数派クラスに偏った予測をする傾向があり、少数派クラスの重要なパターンや特徴を見逃してしまう可能性が高くなります。これは、特に医療診断、金融詐欺検出、製造業の品質管理など、誤った予測が重大な結果を招く分野で特に問題となります。データ不均衡の問題を理解するために、医療分野における疾患診断の事例を考えてみましょう。ここでは、ある稀ながんの早期発見を目的とした研究を想定します。
- データセットの内容: 10,000人の患者データ
- 目的: このデータを用いてがんの有無を診断するモデルを開発
以下はデータの内訳です。
- がん患者: 100人 (1%)
- がんでない患者: 9900人 (99%)
このデータセットでは、がん患者(少数派クラス)とがんでない患者(多数派クラス)の比率が極端に異なります。この不均衡により、モデルはがんでないケースに偏った予測をしてしまいがちです。例えば、すべてのケースで「がんではない」と予測することで高い正答率を示す(正答率99%)ことができますが、その代償として重要な少数派のケース(がん患者)の検出が不可能になります。なぜならば、全てのケースを「がんではない」と予測するからです。このような状況では、モデルががん患者を正しく識別することが極めて重要であり、少数派クラスのサンプルを増やすことが求められます。SMOTEアルゴリズムはこのような場合に有用で、人工的にがん患者のデータを生成してデータセットのバランスを改善することができます。
2. SMOTEアルゴリズムの概要
SMOTE(Synthetic Minority Over-sampling Technique)は、データセットの不均衡を解決するために開発されたアルゴリズムです。この技術は、少数派クラスのサンプルを合成的に増やすことにより、データセットのバランスを改善します。少数派クラスのサンプル数を増やして、データセットのクラス間バランスを改善することで、機械学習モデルは少数派クラスに関するより多くの情報を学習し、その結果、より正確でバランスの取れた予測を行うことができます。SMOTEは、少数派クラスのサンプルから新しいサンプルを合成的に生成しますが、単純なコピーではなく、既存のサンプル間の特徴空間を補間することで、より多様なデータセットを作成します。
3. SMOTEの仕組み
(1)ステップByステップ
SMOTEがどのように機能するのかを具体的なステップに分けて解説します。
ステップ1: マイノリティクラスからサンプル選択
SMOTEはまず、少数派クラス(例えば、がん患者のデータポイント)からランダムにサンプルを選びます。この選択されたサンプルは、新しい合成サンプルを生成する基点となります。
ステップ2: k-最近傍法による近隣サンプルの特定
選択したサンプルのk個の最近傍点(最も近いk個のサンプル)を見つけます。ここでの「最近傍」とは、特徴空間において最も類似しているサンプルを意味します。kの値は、アルゴリズムを実行する際に設定されます。
ステップ3: 新しいサンプル生成
新しい合成サンプルは、選択したサンプルとその最近傍点の間で特徴値を補間することにより生成されます。具体的には、選択したサンプルと最近傍点の特徴値の差を計算し、この差にランダムな値(0と1の間)を乗じたものを元のサンプルの特徴値に加えます。これにより、元のサンプルとは異なるが類似した特徴を持つ新しいサンプルが作成されます。
このプロセスは、バランスの取れたクラス比率を得るまで繰り返されます。結果として、SMOTEは少数派クラスのサンプルを増加させ、データセットの全体的なバランスを改善します。
(2)例: 信用スコア予測の場合
①データの概要
データセットの内容
- レコード: 1000人の顧客データ
- 目的: 信用スコアが低い顧客(信用リスクが高い)の識別
データの特徴量
データの内訳
- 信用スコアが低い顧客(少数派クラス): 100人
- 信用スコアが高い顧客(多数派クラス): 900人
②SMOTEによるデータ生成例
ステップ1: サンプルの選択
選択されたサンプル: 30歳、収入300万円
ステップ2: 2つの最近傍サンプルの特定
最近傍サンプル1: 28歳、収入280万円
最近傍サンプル2: 32歳、収入320万円
ステップ3: 合成サンプルの生成
各最近傍サンプルとの差を計算
ランダムな数値を乗じて新しいサンプルを生成
・最近傍サンプル1を使用した場合
年齢の差: 28−30=−2歳
収入の差: 280−300=−20万円
ランダムな数値(例: 0.5)を乗じる
新しいサンプル:
年齢 30−2×0.5=29歳
収入 300−20×0.5=290万円
最近傍サンプル2を使用した場合
年齢の差: 32−30=+2歳
収入の差: 320−300=+20万円
ランダムな数値(例: 0.5)を乗じる
新しいサンプル:
年齢 30+2×0.5=31歳
収入 300+20×0.5=310万円
このように、複数の最近傍サンプルを使用することで、元のサンプルと似ているが異なる特徴を持つ複数の合成サンプルを生成することができます。これにより、データセットの多様性をさらに高め、より効果的に不均衡問題に対処できます。
4. SMOTEの使用上の注意点
SMOTE(Synthetic Minority Over-sampling Technique)は、不均衡なデータセットに対して非常に有効な手法ですが、適用する際にはいくつかの注意点があります。ここでは、SMOTEを使用する際の主要な注意点を挙げていきます。
連続変数に適したアルゴリズム
SMOTEは本来、連続変数に基づいて設計されています。これは、連続変数の値が補間可能であることを前提としているためです。したがって、元のSMOTEアルゴリズムは、カテゴリカル変数を持つデータセットに直接適用することは適切ではありません。
カテゴリカルデータ変数対応SMOTE
カテゴリカル変数や混合型データセットに対しては、カテゴリカルデータ変数に対応したSMOTEアルゴリズムを利用する必要があります。例えば、SMOTE-NC(SMOTE for Nominal Continuous)は、連続変数とカテゴリカル変数の両方を扱うことができます。
データの品質と過剰適合
SMOTEによって合成されたデータは、元のデータセットの特徴を模倣していますが、実際のデータではありません。過度にSMOTEを使用すると、モデルが過剰適合し、新しい未知のデータに対してうまく一般化できなくなる可能性があります。
データの分布と異常値
SMOTEは元のデータの分布を考慮せずに新しいサンプルを生成します。これにより、元のデータセットに含まれる異常値やノイズが強調されることがあります。したがって、SMOTEを適用する前にデータの前処理とクリーニングが重要です。
モデルの複雑性
SMOTEを使用すると、データセットが複雑になる可能性があります。これにより、モデルの訓練時間が長くなったり、より複雑なモデルが必要になる場合があります。
SMOTEは、データ不均衡の問題を効果的に解決する強力なツールですが、適切な前処理、適正なアルゴリズムの選択、過剰適合への注意が必要です。これらの点を考慮に入れることで、SMOTEを用いたデータの拡張がより効果的になります。
5. SMOTE-NCの仕組み

SMOTE-NC(SMOTE for Nominal Continuous)は、連続変数とカテゴリカル変数を持つデータセットに適用できるSMOTEアルゴリズムです。このアルゴリズムにより、少数派クラスの表現力を高め、よりバランスの取れたデータセットを作成することが可能になります。以下にSMOTE-NCの基本的なステップを説明します。
(1)ステップByステップ
ステップ1: マイノリティクラスからサンプル選択
SMOTE-NCは、まず少数派クラス(例えば、がん患者のデータポイント)からランダムにサンプルを選びます。この選択されたサンプルは、新しい合成サンプルを生成する基点となります。
ステップ2: k-最近傍法による近隣サンプルの特定
選択したサンプルのk個の最近傍点を見つけます。SMOTE-NCでは、この最近傍点の特定において、連続変数とカテゴリカル変数の両方を考慮します。
ステップ3: 新しいサンプル生成
SMOTE-NCは、連続変数とカテゴリカル変数の両方に対して異なるアプローチを取ります。
連続変数に対して: 標準のSMOTEアルゴリズムと同様に、選択したサンプルと最近傍点の連続変数における差を計算し、この差にランダムな値(0と1の間)を乗じたものを元のサンプルの連続変数の特徴値に加えます。カテゴリカル変数に対して: カテゴリカル変数では補間が適用できないため、最近傍点のカテゴリカル変数の値からランダムに一つを選択し、これを新しいサンプルのカテゴリカル変数の値として使用します。このプロセスを通じて、新しい合成サンプルは元のサンプルと似ているが完全には同じではない、という特性を持ちます。この新しいサンプルは、元のデータセットに追加され、データセットの全体的なバランスを改善します。
(2)例: 信用スコア予測の場合
①データの概要
データセットの内容
レコード: 1000人の顧客データ
目的: 信用スコアが低い顧客(信用リスクが高い)の識別
データの特徴量
年齢(連続変数)
収入(連続変数)
雇用形態(カテゴリカル変数:「正社員」「契約社員」「アルバイト」)
データの内訳
信用スコアが低い顧客(少数派クラス): 100人
信用スコアが高い顧客(多数派クラス): 900人
②SMOTEによるデータ生成例
ステップ1: サンプルの選択
選択されたサンプル: 30歳、収入300万円、雇用形態「正社員」
ステップ2: 2つの最近傍サンプルの特定
最近傍サンプル1: 28歳、収入280万円、雇用形態「契約社員」
最近傍サンプル2: 32歳、収入320万円、雇用形態「アルバイト」
ステップ3: 合成サンプルの生成
連続変数(年齢と収入)に対しては通常のSMOTEの手法を適用
カテゴリカル変数(雇用形態)に対しては、最近傍サンプルの中からランダムに一つを選択
最近傍サンプル1を使用した場合
年齢の差: 28−30=−2歳
収入の差: 280−300=−20万円
ランダムな数値(例: 0.5)を乗じる
新しいサンプル:
年齢 30−2×0.5=29歳
収入 300−20×0.5=290万円
雇用形態「アルバイト」
最近傍サンプル2を使用した場合
年齢の差: 32−30=+2歳
収入の差:320−300=+20万円
ランダムな数値(例: 0.5)を乗じる
新しいサンプル:
年齢 30+2×0.5=31歳
収入 300+20×0.5=310万円
雇用形態「契約社員」
このように、SMOTE-NCでは、連続変数に対しては補間を行い、カテゴリカル変数に対しては最近傍サンプルからランダムに選択することで、新しい合成サンプルを生成します。これにより、データセットにおける少数派クラスの表現を強化し、よりバランスの取れた分析を行うことが可能になります。
6. SMOTEのビジネスへの応用
SMOTE(Synthetic Minority Over-sampling Technique)は、ビジネスにおけるデータ分析と予測モデリングにおいて、重要な応用範囲を持ちます。SMOTEがビジネスの各領域でどのように活用されているか紹介します。
顧客のチャーン予測
ビジネスにおいて顧客の維持は重要な課題です。チャーン(顧客の離反)する顧客は通常、全顧客の中で少数派に属します。SMOTEを使用することで、チャーンする顧客のデータを人工的に増やし、より効果的にチャーンを予測するモデルを構築できます。
金融詐欺検出
金融業界では詐欺取引の特定が重要です。詐欺取引は全取引の中で少数を占めるため、SMOTEを適用することでデータセットのバランスを改善し、詐欺検出モデルの精度を高めることができます。
医療診断
医療データにおける稀な病気の診断では、病例が全体の中で少数派となることが多いです。SMOTEを使用して病例のデータを増やすことで、早期発見や診断の精度を向上させることが可能です。
クレジットスコアリング
金融機関では、ローンの返済不能者を予測することが重要です。返済不能者は通常、申込者の中で少数です。SMOTEを利用してこのグループのデータを増やすことで、より正確なクレジットスコアリングモデルを開発できます。
SMOTEは、データ不均衡がビジネス上の意思決定に大きな影響を与える場面で特に有効です。適切に適用されたSMOTEは、データの多様性を高め、モデルの予測能力を向上させることで、より精度の高いビジネス上の洞察を提供します。ただし、SMOTEの使用には注意が必要であり、データの特性とビジネスの要求をよく理解した上で適切に利用することが重要です。
次回に続きます。
◆関連解説記事:データサイエンスとは?データサイエンティストの役割は?必要なツールも紹介
▼さらに深く学ぶなら!
「データ分析」に関するセミナーはこちら!



























