1.はじめに
本記事は、CVPR 2022 に採択された人物検索 (person search) AI に関する論文 "Cascade Transformers for End-to-End Person Search[1]" (以下、論文) の簡単な解説です。
人物検索は、画像から目的の人物を捜し出し画像中の位置を特定する技術です。刑事もののドラマで、AI が防犯カメラ映像から犯人の映っている映像を捜し出し、犯人を四角いボックスで囲んで刑事に知らせるシーンがよくありますが、それを思い浮かべていただければ良いでしょう。
人物検索 AI は、「人を画像から検出する」だけでなく「個人を識別できる」必要があります。AI は人と背景を分離を行うという観点では人一般に共通する特徴を獲得する必要があり、特定の個人を見分けるという観点では個々人の細かい特徴を獲得することが必要となります。このように、相反する 2 種類の特徴を獲得しなければならないということから、単に人検出を行うよりも難しい課題であると言えます。
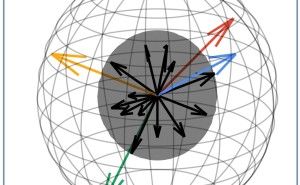
そのほかにも、図 1 に示すような画像中に映る人の大きさや、方向の違い、オクルージョンへの対応も求められます。

図1. 人物検索における課題 [1]
2.モデルの構造
これまで Deep Learning を用いた画像認識や物体検出においては CNN という構造がベースのモデルが主流でした。しかし、2010 年台終盤から Transformer と呼ばれる自然言語処理分野で成功を収めた技術の画像分野への転用が始まり、今では多くの Transformer のみで構成されたモデルや Transformer と CNN のハイブリッドモデルが提案されています。
論文で提案されているモデルは、Cascade R-CNN[2] をベースとした CNN と Transformer のハイブリッド型です。
Cascade R-CNN は、図2 のような構造になっています。
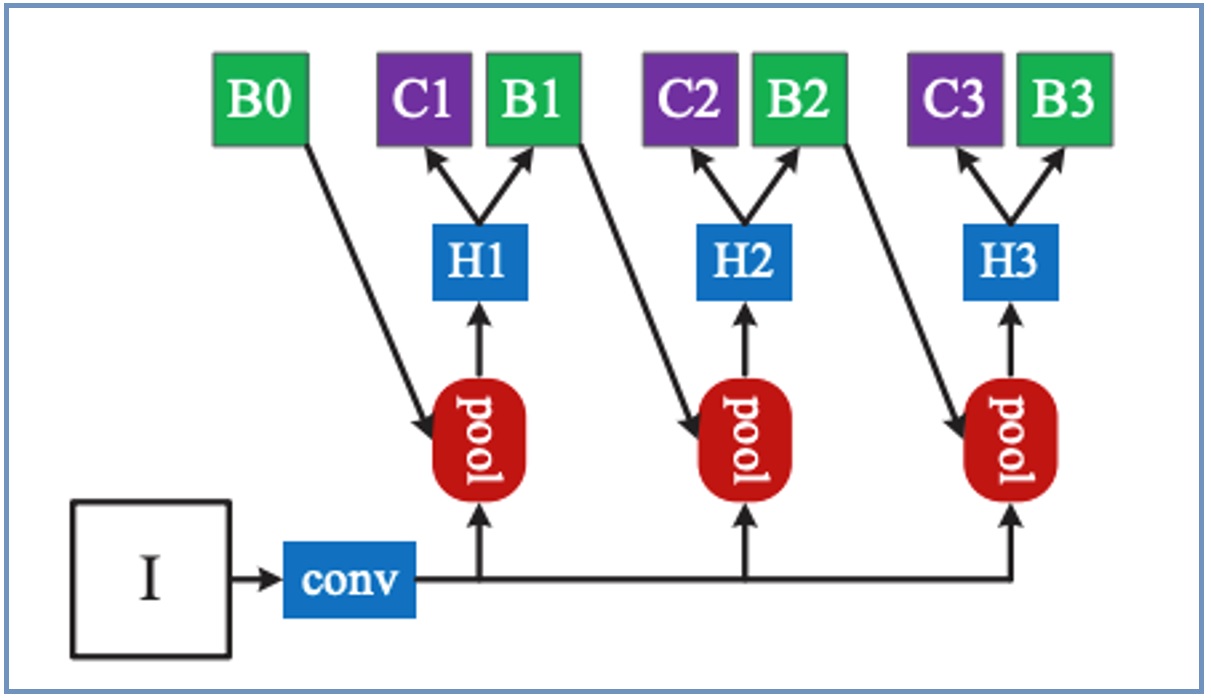
図2. Cascade R-CNN [2]
図中の B0、 B1、 B2、 B3 は bounding box で、B0 は Region Proposal Network (RPN) による bounding box です。I は入力画像、conv は backbone を表しています。Backbone には ResNet-50 が採用されています。 Pool は bounding box に囲まれた領域の抽出を表しています。H1、H2、H3 は network head、C1、C2、C3 はクラス分類を表しています。
Cascade R-CNN では、bounding box の生成をシーケンシャルに複数回行っています。モデルの訓練の際には、IoU の閾値を段階的に上げていきます。これにより、高い IoU の閾値でモデルを最適化可能となり、結果として質の高い bounding box を生成可能なモデルが構築されるという仕組みになっています。
論文で提案されているモデルは、Cascade R-CNN の H1、H2、H3 を transformer と NAE (Norm-Aware Embedding) [3]を用いて構成したものになります。
NAE は、人物検索における「人一般の特徴」と「個人の詳細な特徴」という 2 つの相反する特徴をうまく分離して獲得するために提案された手法です。より具体的には、下図 (文献 3 より引用) のように、特徴空間を極座標を使って表現し、特徴ベクトルのノルムが「人であることの確信度」、特徴ベクトル同士の角度が「同じ人かどうかを示す類似度」になるようにモデルが訓練されます。図 3 中の黒い矢印が背景、それ以外の色の矢印が人を表しています。
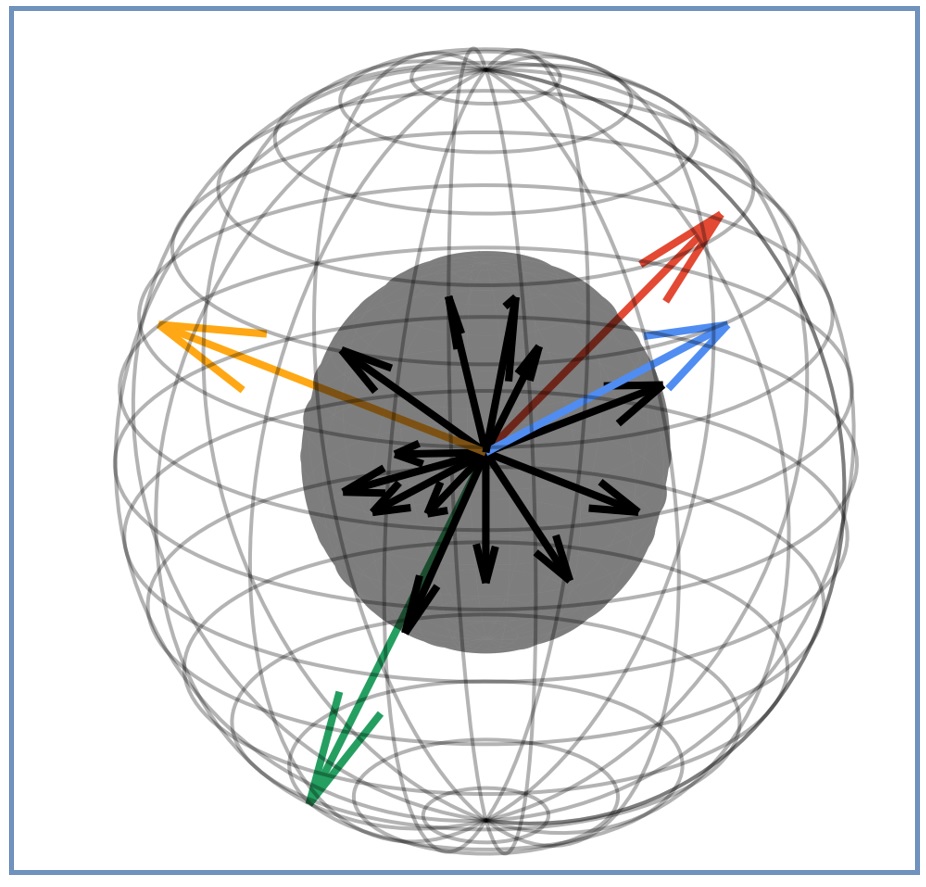
図3. 特徴空間の極座標表現[3]
例えば、ある人が観測されたとき、その人の特徴ベクトルと赤の特徴ベクトルとの間の角度が小さい時、観測された人は赤の特徴ベクトルで表される人と同一人物であると推論されます。
NAE のネットワーク構造は、図4 のようになっています。
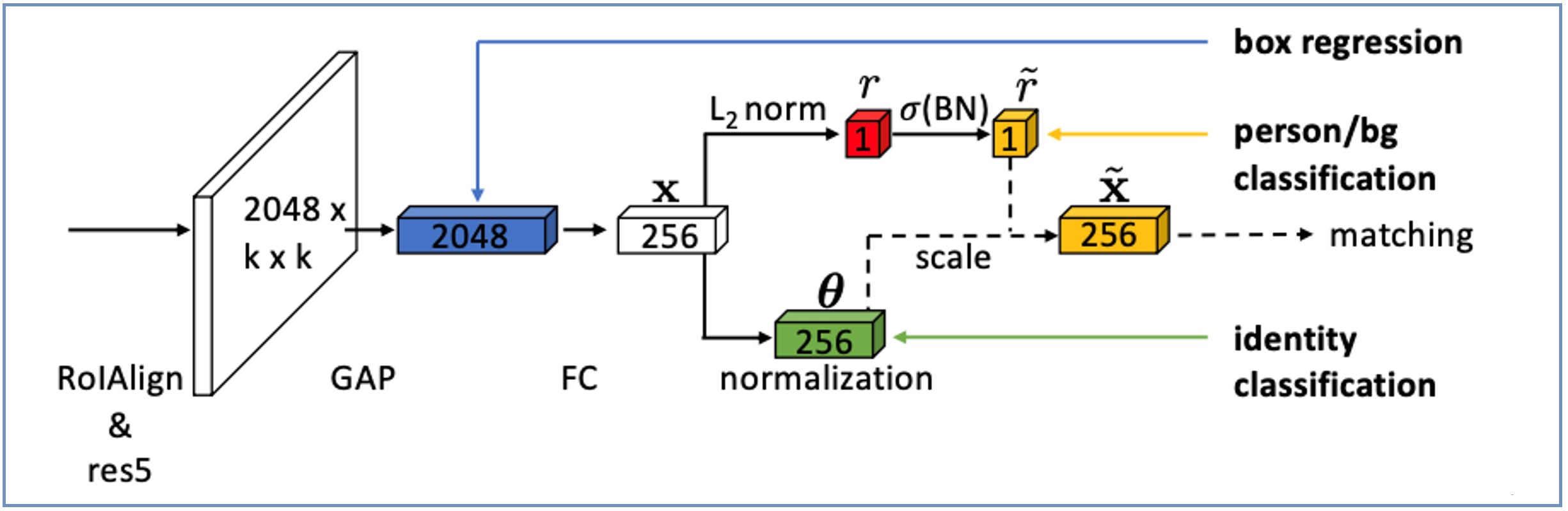
図4. NAE のネットワーク構造[3]
3.おわりに
いかがでしたでしょうか。より詳しくお知りになりたい方は、参考文献を是非ご覧ください。また、論文実装のソースコードも GitHub (https://github.com/Kitware/COAT) に公開されていますので、そちらもご覧ください。とても読みやすいコードになっています。
Morning Project Samurai では、AI に関するご質問や、ご自身のシステムへの AI の組み込みについてのご相談も受け付...
























-守・破・離ー")
関連技術の法的実務の課題と対応の方向性")







