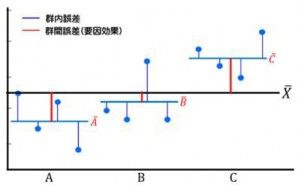
前回のその1に続いて解説します。群内誤差が大きければ群間誤差(要因効果)が観えなくなるので、単純に平均値だけでの評価は危険が伴います。それは郡内誤差が群間誤差がよりも大きい場合は再度同様の試行を行った時、同じようなデータセットが出てくるとは限らないからです。優劣が逆転する事もあり得ます。 解りやすいようにイメージ図を用います。 A,B,C、3つの条件で四回ずつ実験を行う例を示すと群間誤差と群内誤差のイメージは図1の様な感じとなります。
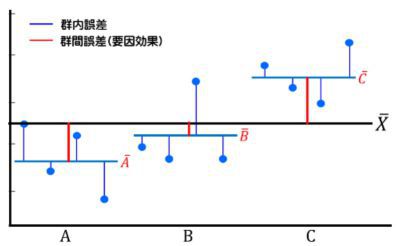
図1.群間誤差と群内誤差
条件AとCは差が大きく直感的に異なる分布と言えそうです。再評価を行っても序列が入れ替わるほど偏ったデータが出現する可能性は低いでしょう。一方AとBを比較すると平均値はBが大きいですが、個別の値を見るとAB双方のばらつき範囲が重なっているので検定を行っても有意差は出ないでしょう。何度も実験を行えば数%~十数%の確率でA>Bとなる場合も生じそうです。開発時は良好で、量産では上手く再現しない場合、この誤差と効果の見極めができていない事も原因の一つとして考えられます。繰り返して再現性を観る事は当然重要ですが、統計的評価も併せて行わないと時間とコストを度外視し安心出来るまで何度も実験を行うことは無理ですし、そもそも何度も試行出来ない評価もあります。
ばらつきを調べる時、群内誤差か群間誤差を切り分ける有効な手法が層別分析です。例えば3台の装置がある場合、号機別でデータの層別を行えば装置間誤差と装置内誤差を知ることが出来ます。原料を2つのサプライヤーから購入していれば原料別で切り分けることにより原料間誤差と原料内誤差を知ることが出来ます。もちろん誤差を生み出す要因は複数あります。 原料、装置、人、処理条件、測定条件、付帯設備、気温・水温・・・ これらのうちどれが最も大きな誤差を生み出しているかをデータ分析で調べることで適切な対策が打てるのです。
誤差評価の活用の場面は製造現場だけではありません。新しい広告宣伝の効果の評価、新企画よる売上改善評価、新メニューの評判など、一見無関係で定性的評価しか出来ない様な事でも数値化により応用が可能です。ばらつきに遭遇した時、層別手法を用いて群間誤差と群内誤差に切り分けるだけでもかなり誤差原因を絞り込むことが容易に...










![ものづくり現場 AI/DX DAY 2026 summer [for Leaders] 20260729 2days開催](https://assets.monodukuri.com/img/2c84e607-d888-41e6-ba9d-c4046b94052f.png)













