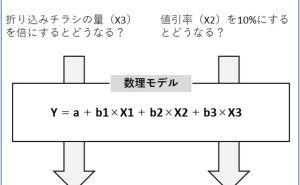
ここ数年、色々なAutoML(自動機械学習)が登場してきました。有料版で勢いがあるのがDataRobotです。GoogleもIBMもMicrosoftなどでもAutoMLサービスを提供しています。国内でもSONYのPrediction oneなど色々なものが登場してきました。RやPyhtonなどのフリーの分析ツールで使える(要は、無料で使える)AutoML(自動機械学習)もあります。RやPyhtonなどのコードを書ける方は、無料で使えるAutoML(自動機械学習)で十分でしょう。GUI(操作画面)以外は有料版に劣るものではありません。
今回は、「データ分析の初学者と自動機械学習」というお話しをします。
【目次】
1.AutoML(自動機械学習)とは?
(1)どのような数理モデルを構築してくれるのか
(2)自動化してくれる範囲
(3)パイプライン最適化
(4)パイプライン最適化の結果は、非常に勉強になる
2.絶対避けるべきAutoML(自動機械学習)ツール
1.AutoML(自動機械学習)とは?
AutoML(Automated Machine Learning)とはその名のとおり、機械学習の一部の手順を自動化したものです。ただし、自動化される範囲はツールによって異なります。
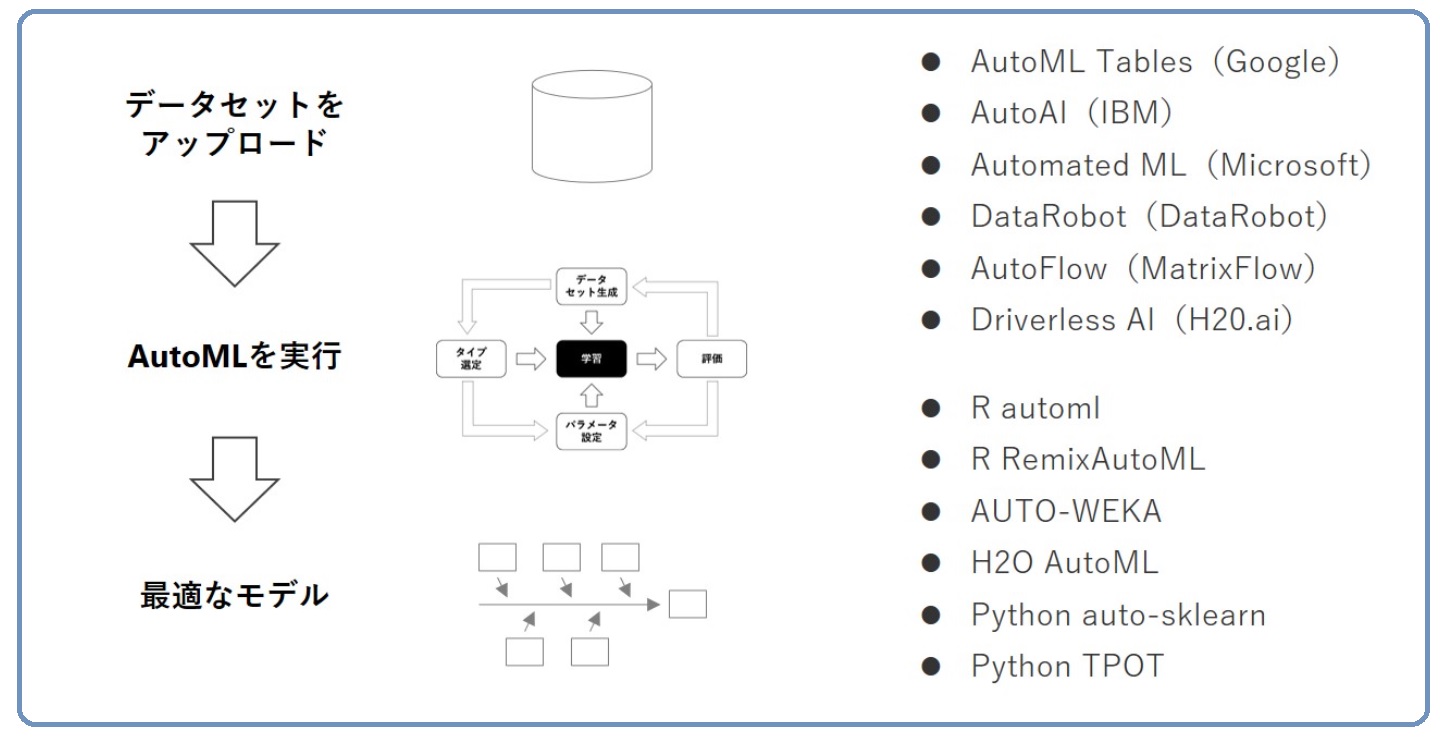
非常に単純化した説明をすると……
- データセットをAutoML(自動機械学習)ツールに入力する
- AutoML(自動機械学習)で予測モデルを構築する
- AutoML(自動機械学習)で構築した予測モデルが出力される
……といった感じです。AutoML(自動機械学習)を実施するとき、実際はもう少し手間(目的変数や説明変数の指定や評価関数の指定など)があります。
(1)どのような数理モデルを構築してくれるのか
どのツールも、基本的に「予測」のための数理モデルを自動で構築します。過去の現象や傾向、パターンなどを解釈するための数理モデルではなく、未来を予測するためのモデルです。
予測の種類は主に次の2種類です。
- 数値を予測する回帰モデル(売上予測、受注件数予測、など)
- 分類を予測する分類モデル(受注 or 失注、継続 or 離反、など)
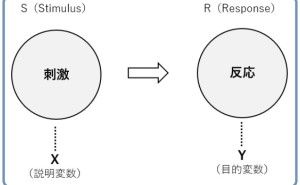
ある評価指標が最適化するように、予測モデルを構築します。ちなみに、ロジスティック回帰モデルは分類モデルですが名称に「回帰」が付いています。厳密には分類モデルは、目的変数Yが二値や多値の回帰モデルなので、回帰モデルに包含されます。
(2)自動化してくれる範囲
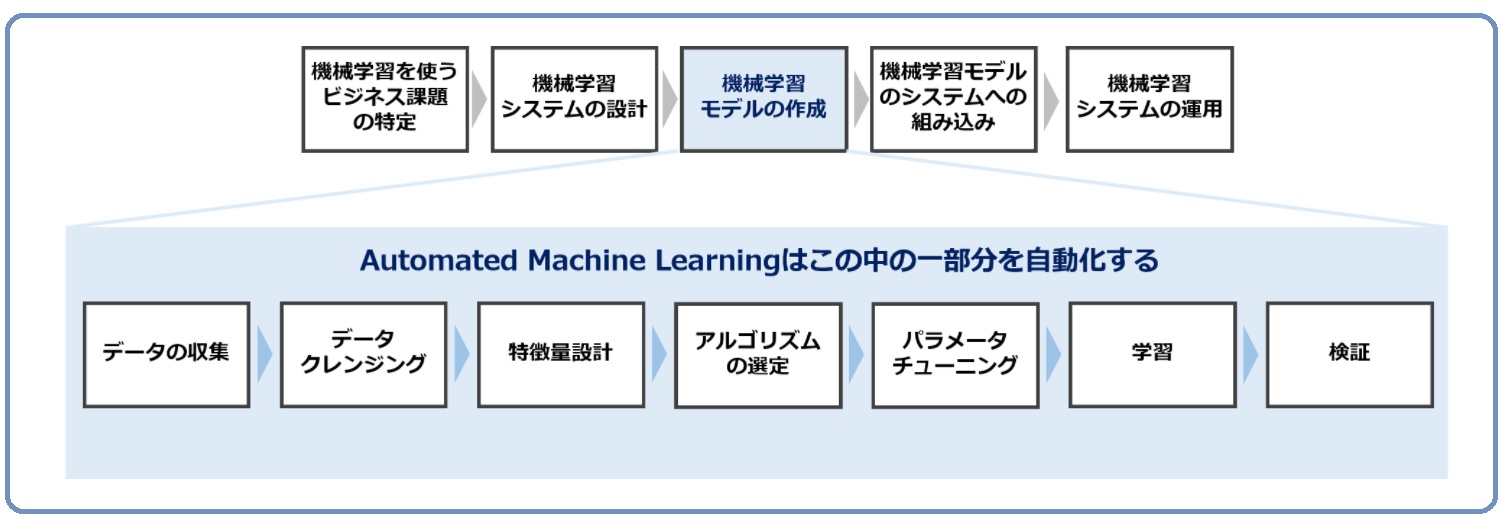
AutoML(自動機械学習)ツールによって、自動化してくれる範囲が異なります。共通しているのは、予測モデルの構築の部分です。AutoML(自動機械学習)ツールによっては、予測モデルの構築前の処理も自動化してくれます。
予測モデルの構築前の処理とは、特徴量の生成と選択です。特徴量とは説明変数Xのことで、目的変数Yを予測するときに使うデータです。
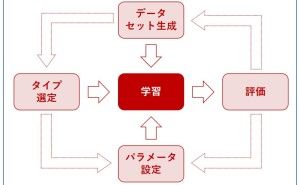
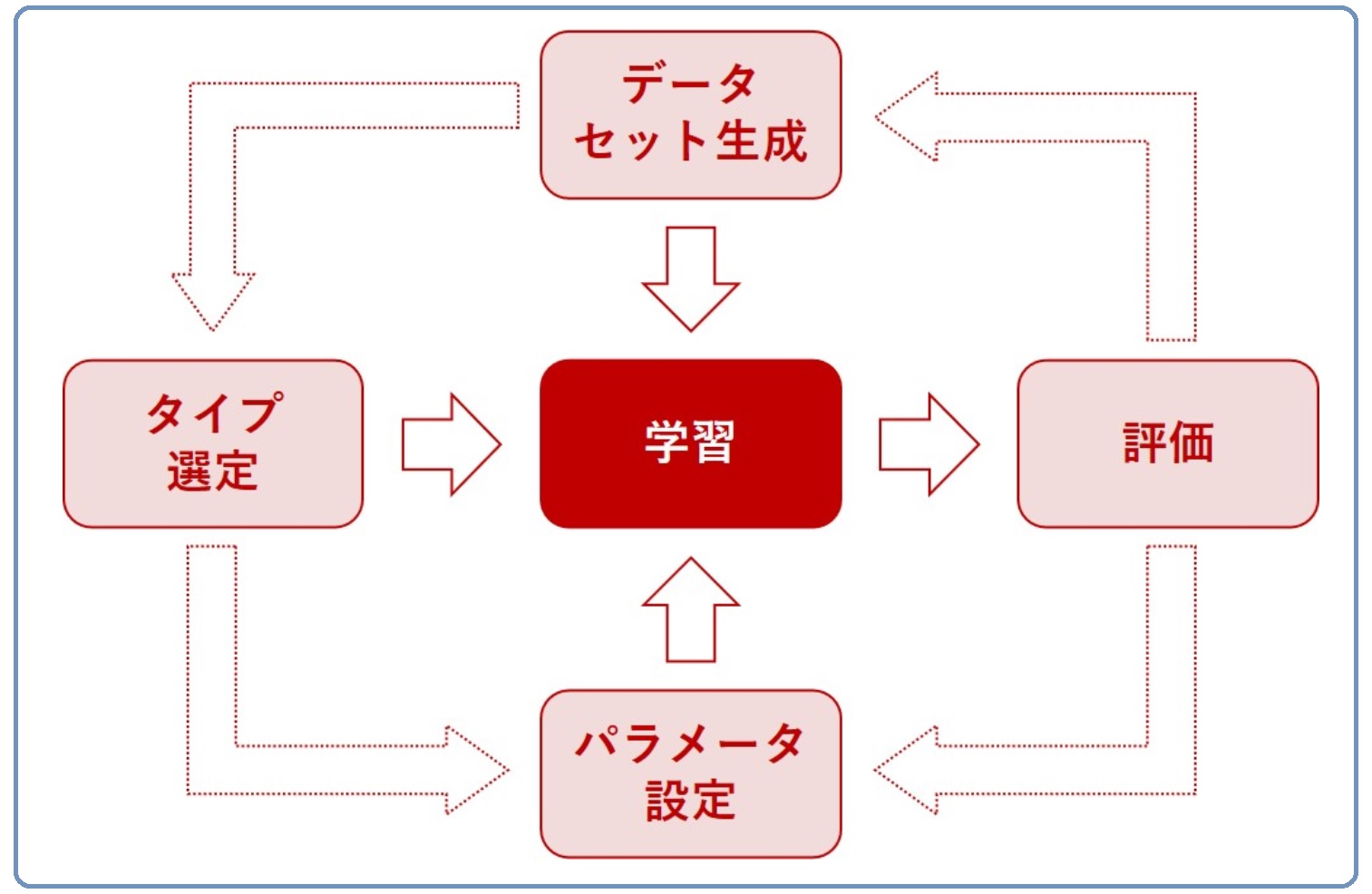
(3)パイプライン最適化
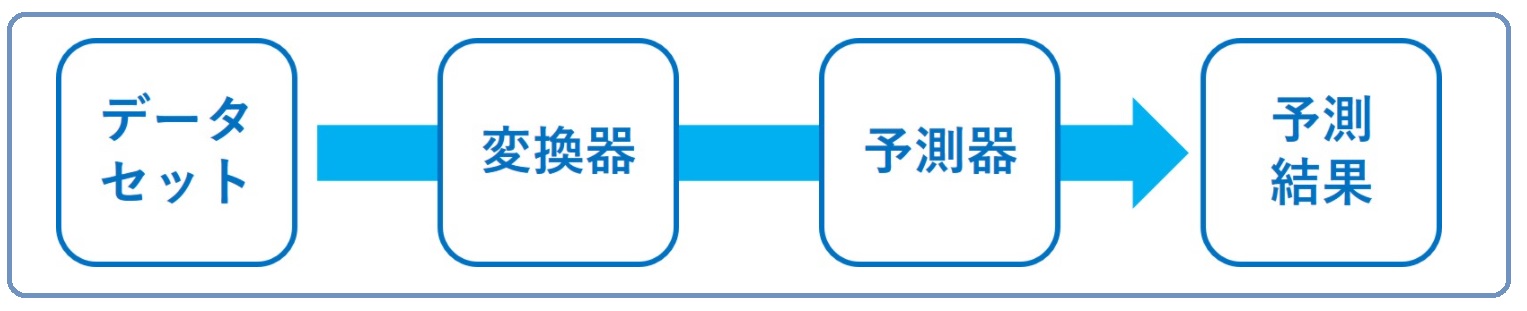
ここで、次のような用語を使い説明します。
- 変換器:特徴量から新たな特徴量を生成する
- 予測器:学習済み予測モデル
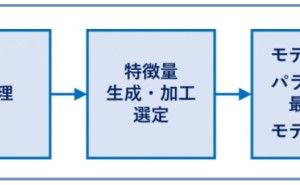
以下は、予測するときの流れです。
データセット
↓
変換器(特徴量の生成と選択)
↓
予測器(回帰モデルや分類モデル)
↓
予測結果
ちなみに、変換器は1つではなく複数になる場合もあります。変換器を通して、作られた特徴量は古い特徴量を含むこともあります。どういうことかと言うと、古い特徴量に新しい特徴量をどんどん追加する感じです。このような、変換器と予測器の組み合わせ(流れ)をパイプラインといいます。
AutoML(自動機械学習)ツールによっては、パイプラインの生成を自動化してくれます。生成するからには、パイプライン最適化を目指します。
(4)パイプライン最適化の結果は、非常に勉強になる
AutoML(自動機械学習)ツールを使ったら、必ずどのようなパイプラインになっているかを確かめましょう。可笑しなパイプラインになっていないかチェックするという意味合いもありますが、それ以上に最適化されたパイプラインを見ることは非常に勉強になります。どのようにして特徴量を新たに生成し選択したのかという技術的な勉強です。
あまり数理モデル構築に慣れていない方であれば、特徴量の作り方や選び方を学ぶきっかけになります。さらに、そもそもデータセットだったのか垣間見れることもあります。もちろん、出力された予測モデルがどのようなモデルなのかを勉強するのも...