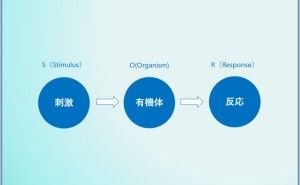
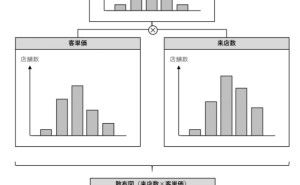
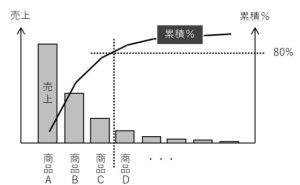
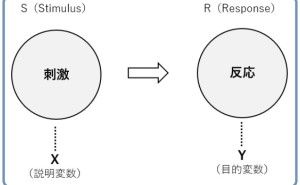
IT化を進めれば、その副産物としてデータは発生します。そのデータを保存さえしていれば、その副産物としてのデータを分析し、何かに活用することができます。ただ、データを副産物として扱う限り、データは活用しにくい状態で保存され続けます。そこで、いざデータ分析や数理モデルを構築しようとすると、データ整備地獄が生まれます。今回は「データは副産物ではなく血液である」というお話しをします。
【目次】
1. データ整備地獄
2. どのような状態のデータが必要なのか?
3. 活用イメージが湧くか?
4. データ活用ストーリー
5. データが血液になるとき
【この連載の前回:データ分析講座(その264)顧客満足度・探索意向率・NPSとはへのリンク】
◆【特集】 連載記事紹介:連載記事のタイトルをまとめて紹介、各タイトルから詳細解説に直リンク!!
1. データ整備地獄
データを分析する前に、データ整備のため多大な時間を犠牲にした人も多いと思います。それなりの分析に使われたことのないデータは、ほぼ汚いです。どう汚いかは一言では言えませんが、そのまま集計や分析するのが怖いぐらい汚く、そこから得られた結果は、間違った方向性へ導く可能性が高いです。そのため、多大な時間を使い、データを綺麗にする作業が発生します。
それがデータ整備地獄です。そのため、手軽にデータ分析や数理モデルなどを構築することができず、常にデータ整備を実施するという作業が入ってしまいます。であれば、最初からデータが綺麗な状態を保てるようにすればいいのでは、となります。
2. どのような状態のデータが必要なのか?
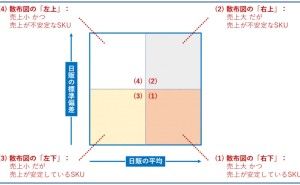
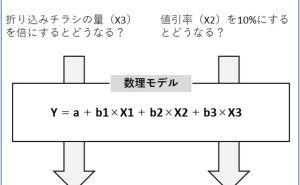
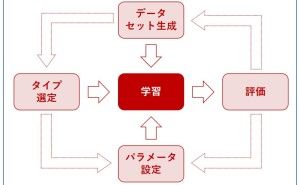
仮に、データが綺麗な状態を保てたとしても、それがデータ分析や数理モデル構築しやすい状態かは、別問題です。データは綺麗でも、データ分析や数理モデル構築のし難い状態が存在します。そこで問題になるのが「どのような状態のデータが必要なのか?」ということです。答えは簡単で「データ分析や数理モデル構築のし易い状態」となります。では、データ分析や数理モデル構築のし易い状態とは、どのような状態でしょうか?
3. 活用イメージが湧くか?
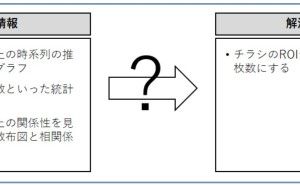
どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などによって、データ分析や数理モデル構築のし易い状態は変わります。ということは、どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などが分かっていればいいことになります。
この、どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などが分からないケースが多々あります。分からないケースの多くは、活用イメージが明確でない場合が多いです。どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などは、その分析結果や予測結果などを、どのように活用するのかに依存します。
活用イメージが分かれば、どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などが分かり、どのようなデータ分析をするのか? どのような数理モデルを構築するのか? などが分かれば、どのような状態のデータが必要なのか?が分かります。そう考えると、活用イメージのないまま、データを整備し綺麗にする作業は非常に危険です。
4. データ活用ストーリー
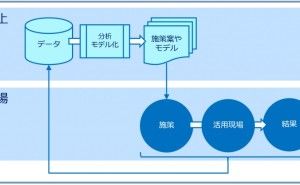
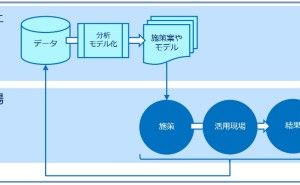
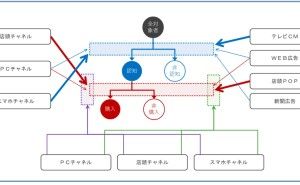
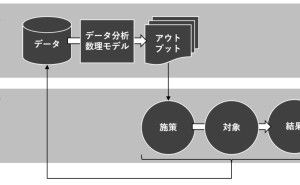
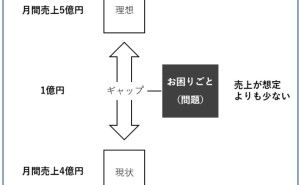
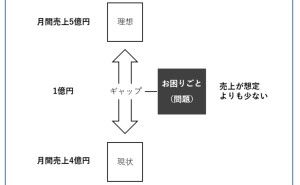
データが情報(データ分析や予測結果など)に変わり、情報(データ分析や予測結果など)がビジネス成果(Before→After)に変わる、この流れがデータ活用ストーリーです。
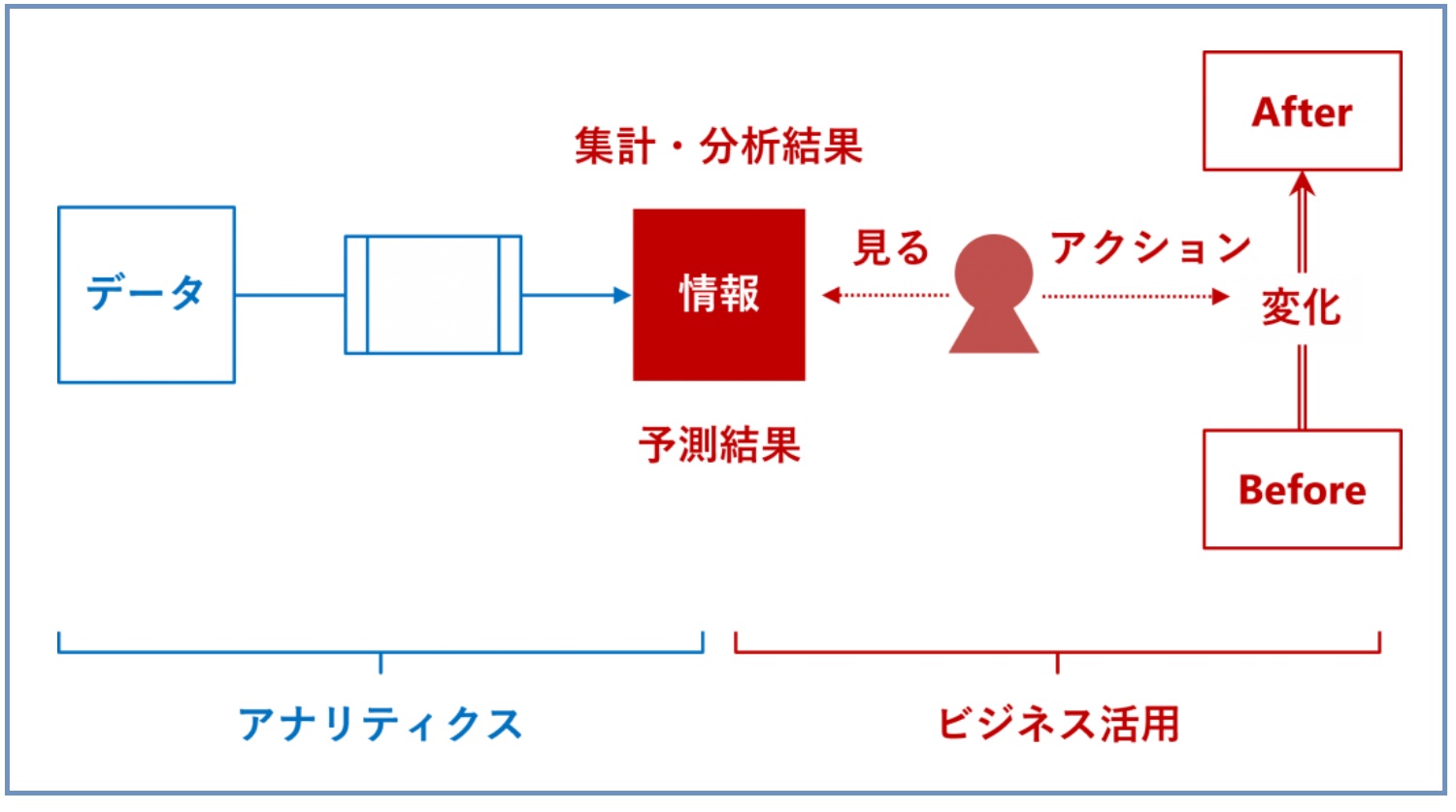
データ活用ストーリーを設計するときは、逆算です。
- どのようなビジネス成果(Before→After)を出したいのか
- そのために、どのような情報(データ分析や予測結果など)を、どのように活用するのか
- そのために、どのようなデータ分析や数理モデル構築などが必要なのか
- そのために、どのようなデータが必要なのか
非常にシンプルなことです。
5. データが血液になるとき
あるビジネスのある特定の一部分に着目し、データ活用ストーリーを構築し、データからビジネス成果を出すのもいいでしょう。そのとき、IT化の副産物であったデータが、単なる副産物以上の何かに変わります。目指すべきは、副産物からの脱却ではなく、その先のビジネス活動の血液です。多くの場合、たった1つのデ...