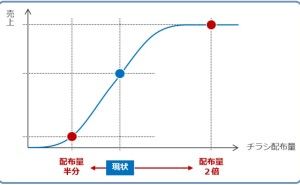
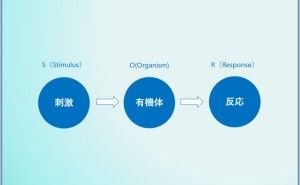
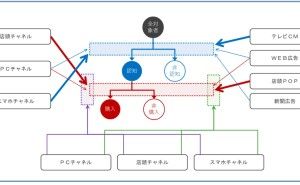
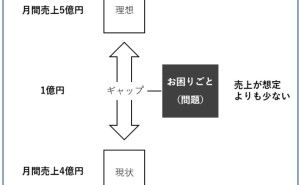
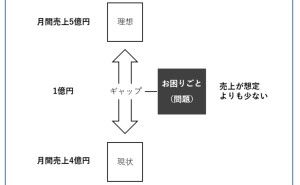
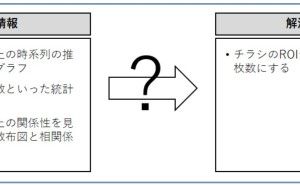
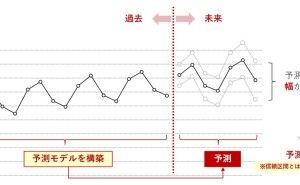
◆ ビジネス系のデータは、時系列が多い。そこで、先ず3つの視点で分析。
今どきの高校生は、統計学やデータ分析を普通に授業で学んでいます。私が高校時代も授業がありましたが、今どきは、小学校から高校生までそのための授業があります。今どきのセンター試験対策の参考書に「データ分析」というのがあるぐらいですから。国をあげて統計学・データ分析教育に、力を入れているようです。
この話をすると驚かれます。今どきの子供たちは、「データ分析」を当たり前の知識として身に着け、これからの社会にでてくる予定です。その前の世代(ゆとり世代)以前は、このような教育は受けていません。学校の先生方は大変ですが、日本社会としてはよい傾向なのだと思います。
小学校5~6年生あたりの統計学・データ分析系のドリルと見てみてください。結構、良い問題がたくさんあります。ほとんどが、データを整理して読み取るという問題ですが、今どきの大人でも難しいと感じる人は多いと思います。それはさておき、大学の統計学の授業ででてくるデータと、社会のデータ(ビジネス系のデータ)では大きな違いがあります。
大学の統計学の授業ででてくるデータの多くは、トランプやサイコロなどのデータや、ある決められた一時期のデータ(例:試験の得点データ、アンケートデータ、身体データなど)だったりします。社会に出ると、分析対象のデータの多くは、圧倒的に時系列系のデータです。
大学の統計学の授業にも、時系列解析というのがありますが、どちらかというと専門性の高いもので、非常に小難しいものです。実務で活用すると、二の足を踏んでしまいます。今回は、ビジネスの現場で時系列データに遭遇したときに、まず押さえておくべき3つの視点の分析を紹介します。一度試していただければ、それなりの分析をできるようになると思います。
1. データ分析:ビジネスの世界は、時系列データで溢れている
ビジネスの世界は、本当に時系列データで溢れています。売上データやコストデータ、GPSの位置データ、工場などのセンサーデータなどです。時系列データとは、時間の概念のあるデータです。よくタイムシリーズデータと呼ばれます。
一方、ある決められた一時期のデータをクロスセクションデータと呼びます。こちらは、ほぼ同じ時間のデータなので時間の概念を、ほぼ無視して分析します。例えば、ある年の男性50代の体重の平均を計算したり、年齢によるBMI(体重と身長の関係から肥満度を示す体格指数)の関係を分析したり、各店舗の販促コストや店舗規模と売上の関係を分析したりします。例えば、年齢によるBMIも、時間軸によってどのように変化するのかを分析すると、それはタイムシリーズデータと呼ばれ、時系列解析の範疇になります。例えば、各店舗の販促コストや店舗規模と売上の関係も、時系列でその関係がどのように変化するのかを考えるならば、時系列解析の範疇になります。
ビジネスの多くは、データに時間という概念がついて回ります。その時間という概念を分析したいという欲求は強いと思います。なぜならば、過去の一時期だけを分析するだけでなく、その先の現在や未来を分析対象にしたいからです。要するに、過去・現在・未来という時間でビジネスを考えるならば、必ず時系列解析というデータ分析に、足を突っ込むことになります。
2. データ分析:時系列データを、時系列データとして扱わない分析が多いかもしれない
時系列解析の教科書を読むと、多くの人が挫折します。小難しいからです。一般的な統計学の基礎的な教科書と比べて、結構難しくなります。
私の所感です。移動平均や指数平滑化ぐらいまでなら理解できるが、自己相関や自己偏相関、単位根検定、ARIMA、Box-Cox変換が登場するあたりから多くの人は挫折し、定常性という概念が執拗に登場すると完全に挫折している印象があります。そして、多くの人は、時系列データを折れ線グラフで眺めるだけか、時系列性を無視して分析するか、RやSAS、SPSSなどの統計パッケージにある時系列解析モデル(多くの場合は、ARIMAモデル)で乱暴に分析したりします。
時系列性を無視して分析するとは、例えば回帰分析するときに、時系列データの時系列性を無視して、そのまま回帰分析をしてしまうことです。週ごとに売上と販促費のデータがあった場合、そのまま回帰分析を実施したりします。時系列データなので、本当は売上に季節の周期的な影響もありますし、販促の効果も少し遅れて出てくることもあります。意図をもって、時系列性を無視して分析するならば、解釈するときに補えばよいですが、そうでないと、分析結果を読み誤る可能性があります。
3. データ分析:時系列データに対する、3つの視点の分析
先ず、時系列の分析をするとき、単位根検定、ARIMA、Box-Cox変換だのを考える必要はありません。データの平均や相関係数などを求めるぐらいな気軽な感じで、時系列の分析すればよいです。例えば、以下の3つの視点のデータ分析を、手軽な感じでやってみましょう。
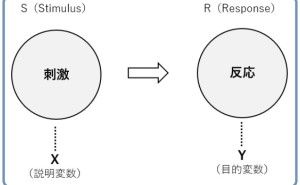
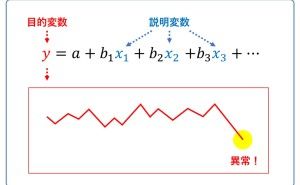
- (1) 目的変数Y(例:売上など)の分析
- (2) 目的変数Yと説明変数X(例:チラシの配布量や値引き率、降水量など)の関係性の分析
- (3) 説明変数X(例:チラシの配布量や値引き率、降水量など)同志の分析
最も身近な統計モデルである「回帰モデル」で説明します。時系列性を無視した回帰モデルであれば、目的変数Y(例:売上など)を説明変数X(例:チラシの配布量や値引き率、降水量など)で表現する(もしくは、予測する)モデルになります。時系列性を考慮した回帰モデルは、目的変数Y(例:売上など)の周期性や説明変数X(例:チラシの配布量や値引き率、降水量など)のラグ性(遅延効果など)も組み込んだモデルになります。
ビジネス活用を考えたとき、 「時系列性を無視した回帰モデル」と「時系列性を考慮した回帰モデル」の大きな違いは、目的変数Yの「周期性」と説明変数Xの「ラグ性」(遅延効果など)を組み込むかどうかにあります。
(1)の「目的変数Y(例:売上など)の分析」で「周期性」を、(2)の「目的変数Yと説明変数X(例:チラシの配布量や値引き率、降水量など)の関係性の分析」で「ラグ性」を分析します。(3)の「説明変数X(例:チラシの配布量や値引き率、降水量など)同志の分析」は、時系列性を考慮するかどうかに関係なく、マルチコ(多重共線性)という回帰モデル上よろしくない現象を避けるために行います。マルチコ(多重共線性)とは、説明変数間で相関係数の絶対値が大きなときに起こるやっかいな減少で、上手く回帰モデルを構築できなくなります。
4. データ分析:ある小売店の例
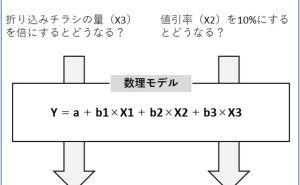
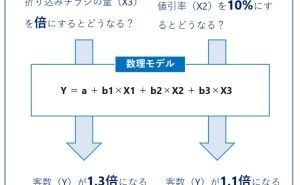
ここでは、主に(1)の「目的変数Y(例:売上など)の分析」で「周期性」と(2)の「目的変数Yと説明変数X(例:チラシの配布量や値引き率、降水量など)の関係性の分析」について、ある小売チェーンの例で説明します。この小売りチェーンは、全国に1,000店舗ほどあります。店舗ごとに日販(1日の売上高)を販促や天候などで予測する回帰モデルを構築しました。
目的変数Y:日販(1日の売上高)
説明変数X1:チラシ配布量(新聞の折り込みチラシ)
説明変数X2:値引き率(ある程度店長に裁量がある)
説明変数X3:降水量(予測時には天気予報を使う)
簡単のため、説明変数は3つで考えていきます。
(1) 目的変数Y(例:売上など)の分析
日販(1日の売上高)のみを分析します。時系列性を考慮したとき、 過去の日販(1日の売上高)との関係性を分析します。
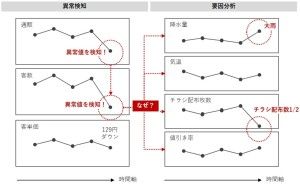
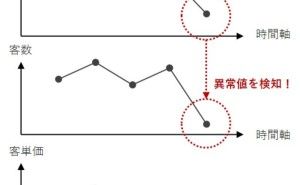
具体的には、1日ずれの日販、2日ずれの日販、…… と、ずらしたデータを複数作り、元の日販との関係性を分析します。よくあるのは、相関係数を求めることです。小売店の場合ですと、7日ずれごとに相関係数が大きくなります。要するに、「元の日販」と「7日ずれの日販」の相関が高くなります。言い換えると、1週間前の日販との相関が高くなります。1週周期があるからです。土・日に日販が跳ねあがり、日曜日明けに日販が落ちるという周期です。
このように、過去の日販(1日の売上高)との関係性を分析することで、周期性を炙り出していきます。多くの場合、1週間周期と1か月周期、年周期(季節変動)が小売店の場合現れます。要するに、複数の周期が交じり合っています。さらに、3連休や大型連休の長さのような要因も、複雑に絡まってきます。これだけでも、時系列解析っぽくないでしょうか。
回帰モデルに周期性を考慮するときは、説明変数として新たに周期性を表現する変数を作り組み込めば済みます、例えば、1週間周期であれば曜日変数(曜日ごとにダミー変数を作る)を導入したり、1週間前の日販を説明変数として使ったりします。ちなみに、ARIMAモデルはこのような周期性などを精緻にモデル化したものです。
(2) 目的変数Yと説明変数X(例:チラシの配布量や値引き率、降水量など)の関係性の分析
目的変数である「日販」と、説明変数である「チラシ配布量」「値引き率」「降水量」の関係性を分析します。時系列性を無視した回帰モデルでも、この分析は必要ですが、時系列性を考慮するともう少し深堀します。
例えば、「降水量」は当日の「日販」にダイレクトに影響を及ぼすでしょう。「チラシ配布量」はどうでしょうか。金曜日に折り込みチラシとしてチラシを配布した場合、その効果が出るのはおそらく土・日です。土・日に向けてチラシを配布しているのだから当然といえば当然です。このような場合、「チラシ配布量」の「日販」への効果にはラグ(ずれ)があります。時系列性を考量する場合、このラグをどのくらいあるのかを分析します。
この例の場合、1日ずれのチラシ配布量、2日ずれのチラシ配布量、…… と、ずらしたデータを複数作り、日販との関係性を分析します。よくあるのは、相関係数を求めることです。金曜日にチラシを配布しているので、恐らく日販と相関が高いのは「 1日ずれのチラシ配布量 」と「2日ずれのチラシ配布量」です。このようにして、説明変数X(例:チラシの配布量や値引き率、降水量など)のラグ性(遅延効果など)を分析していきます。
ここまでやると、かなり時系列解析っぽくなるのではないでしょうか。回帰モデルに説明変数のラグ性を組み込むときは、「 1日ずれのチラシ配布量 」や「2日ずれのチラシ配布量」を新たな説明変数として考えます。このように、時系列性を考慮すると、どんどん新たしい説明変数が増えていきます。
(3) 説明変数X(例:チラシの配布量や値引き率、降水量など)同志の分析
説明変数同志の相関係数の絶対値が高い場合、マルチコ(多重共線性)というよろしくない症状が出てきます。上手く、回帰モデルが構築できないのです。具体的には、回帰モデルのパラメータである各説明変数の係数がおかしな値になります。プラスであるべきところがマイナスになったりします。
このマルチコ(多重共線性)という症状は、時系列解析特有のもの...