【この連載の前回:データ分析講座(その219)現場感とデータ分析へのリンク】
データ分析・活用を始めようと考えたとき、データ収集から始めることがあります。そのとき、完璧にデータを集めようと考える人も少なくありません。しかし、データ分析・活用(データサイエンス実践)をする前に想像する必要そうなデータは、妄想にしかすぎません。今回は、「完璧にデータを集めなければならないという勘違い」というお話しをします。
【目次】
1.どう活用していいか分からない問題
2.妄想と現実のギャップ
3.データにも80:20の法則がある
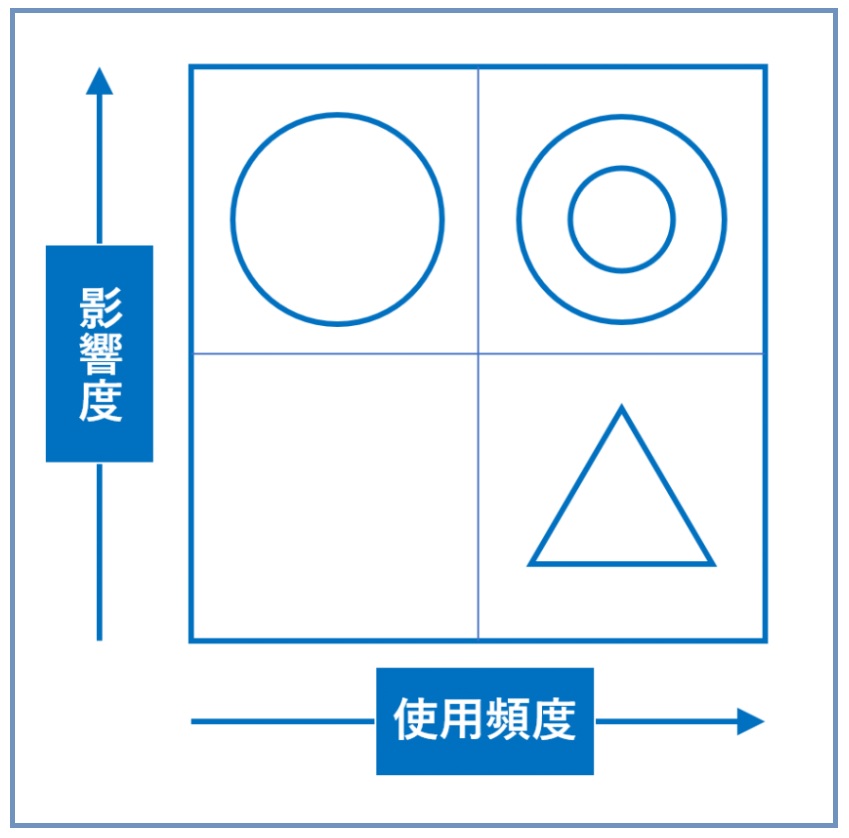
4.2つの視点(使用頻度と影響度)
(1)使用頻度:よく使うデータ
(2)影響度:影響の大きなデータ
1.どう活用していいか分からない問題
いざデータ活用を始めようと考え、データをある程度集めたとき、次にようなつぶやきは以前からあります。「このデータ、どう活用していいか分からない」目的を明確に定めても、このつぶやきは起こりえます。
データ分析・活用(データサイエンス実践)をする前に、データを完璧に把握することは難しいのです。他社を参考にしても、自社の他部署を参考にしても、難しいのです。一人一人の人間が異なるように、データ分析・活用(データサイエンス実践)も異なります。参考にはなりますが、まったく同じにはなりません。
2.妄想と現実のギャップ
要するに、妄想と現実にはギャップがあるということです。データ分析・活用(データサイエンス実践)をすると、絶対必要と思ったデータがそれほど必要でなかったり、あればいいかなぐらいのデータが必要不可欠だったりします。想像もしなかったデータが見えたりします。多くの場合、想像していたデータとは異なるデータが必要になるのではないでしょうか。
何が必要なのかは、今あるデータや手に入りやすいデータだけででもいいから、データ分析・活用(データサイエンス実践)を実施してこないと見えてきません。
そのときはじめて……
- すでにあるデータは?
- 追加で入手できそうなデータは?
- 購入できそうなデータは?
- 他のデータで代替できないか?
……などを検討し、データ分析・活用(データサイエンス実践)を実施しながらデータ収集を検討し実施するのがいいでしょう。
3.データにも80:20の法則がある
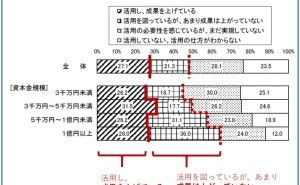
パレートの法則で有名な「80:20の法則」ですが、データの世界にも当てはまる気がします。集めたデータが平等に使われるのではなく、よく使われるデータと、あまり使われないデータに分かれると言うことです。また、同じように使われたデータでも、影響度が大きいデータと、そうでもないデータもあります。
4.2つの視点(使用頻度と影響度)
幾つかの視点がありますが、例えば次の2つの視点で考えると分かりやすいでしょう。
- 使用頻度
- 影響度
絶対集めるべきデータは、使用頻度が高くかつ影響度の大きなデータです。データ分析・活用(データサイエンス実践)をする前や、データ分析を実施したり数理モデルを構築する前に、完璧に把握することは、非常に難しいと思います。
(1)使用頻度:よく使うデータ
データ分析・活用(データサイエンス実践)を色々実施していくと、よく使うデータとそうでもないデータがあることに気が付くと思います。とりあえずこのデータ項目はデータセットに含めておこう、という形で常にデータセットに登場するデータ項目があります。一方で、まったくデータセットに登場しないデータ項目もあります。
データ分析・活用(データサイエンス実践)をする前に、ある程度想像も付きますが、たまに想像もつかないようなデータ項目が、頻繁に活用されることがあります。業種や企業、部署などによって、頻繁に活用されるデータ項目が微妙に異なってきます。
1点注意点があります。データセットに登場しないデータ項目の理由が、欠測値や異常値だらけでデータが不完全であるという理由や、データ収集されていないという理由なども考えられます。「データが不完全であるという理由」や「データ収集されていないという理由」などの理由で、データセットから除外するのは止めましょう。必要そうであれば、不完全であろうが収集されていなかろうが、データセットの中に含めておきましょう。
実際は、データ分析やモデル構築などには使いませんが、「ちゃんとしたデータを集めよう」「データ収集する仕組みを作ろう」という感じの意識づけというかプレッシャーにもなりますし、「本当は必要だけど考慮されていない情報が何か」(解釈上重要)が分かり...