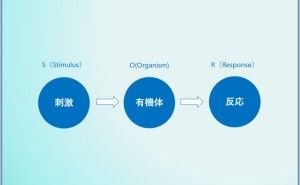
◆ ぐれるAI、オタクになるAI
フェイクニュースという言葉があります。ねつ造の有無とは関係なく、結果的に誤った偽情報を報道することですが、それと同等なのが正しいかどうか分からない状態の情報を報道してしまうことです。問題は、この偽情報が正しいかどうか分からないものなのに、多くの人が信じることで「正しい情報」と見なされてしまうことです。この問題は人間だけでなく、データサイエンス全般、最近流行りの機械学習やAIにとっても、とても大きなことです。今回は「ぐれるAI、オタクになるAI」というお話しです。
1、「女性はマルチタスクが得意」という都市伝説
例えば「女性はマルチタスク※1が得意」という都市伝説があります。都市伝説ではないかもしれませんが、科学的根拠は今のところなさそうです。この根拠になっているのは「右脳と左脳の半球間の神経の束の部位である脳梁(のうりょう)※2が、女性は男性に比べ厚い」という研究結果です。この研究のサンプルが20人と少なかったため、100人に増やして研究がされました。その結果「脳梁(のうりょう)の厚さは男女で差がない」という結論に至りました。100人でも少ないということなのか、その後イスラエル・テルアビブ大学のジョエル教授のグループは、1,400人を超えるサンプルで研究をしましたが、結論は同じで脳による性差は認められない、ということでした。
しかし「女性はマルチタスクが得意」という情報だけが正しいものとして生き続けています。なぜでしょうか。「女性はマルチタスクが得意」の方が「マルチタスクの得意不得意に性差なし」よりも、話題性というか面白みがあるからでしょうか。この手の研究は今でも実施されているようで、結論が二転三転しています。よく分からない、というのが本当のところではないでしょうか。
※1. マルチタスク=複数の作業を同時、もしくは短期間に並行して切り替えながら実行すること
※2. 脳梁=左右の大脳皮質の間で情報をやり取りする経路
2、フェイクなデータの存在は由々しき事態
データサイエンスやAIにとって、フェイクなデータの存在は由々しき事態です。そのデータで構築した予測モデルの予測結果は正しいでしょうか。そのデータで学習したAIはどうなるのでしょうか。あまりよろしくないことだけは分かります。誤った結論や行動につながる可能性があります。正しくないデータが混じっていても、それなりの精度の予測モデルが構築できたり、AIが学習することができたりすれば問題はないかもしれません。
3、AIチャットボット ~ ぐれた「Tay(テイ)」、オタクな「りんな」
最近何かと話題のAIはどうでしょうか。身近なAIにチャットボットというものがあります。文章や音声を通じて会話を自動的に行うプログラムのことです。身近過ぎて、意識しないで生活している人も多いかもしれません。
マイクロソフト社のアメリカのAIチャットボット「Tay(テイ)」(19歳女性を想定している言われている)が一時期有名になりました。「Tay」はTwitterなどで簡単な会話ができるAIチャットボットで、他のユーザとの会話を通してデータを集め学習し成長します。なぜ有名になったのかというと、「Tay」がアメリカで暴言を吐きまくったからです。人種差別的発言や陰謀論、ヘイトスピーチなどです。
では、同社の日本のAIチャットボット「りんな」(女子高生を想定している言われている)はどうでしょうか。こちらも「Tay」と同様に簡単な会話を通してデータを集め学習し成長します。LINEやTwitterで会話ができます。2019年3月に高校を卒業し、同年4月に歌手デビュー(エイベックス・エンタテインメント)しました。日本のAIチャットボット「りんな」は「Tay」とは全くの別人に成長しました。オタクになったのです。
4、データ環境でAIの成長は異なる
このようにデータ環境によって、AIの成長が大きく異なります。つまり、どういったデータ環境(もはや教育環境といってもいいかもしれない)で学習させるかで、AIがどのように成長するのかが決まります。子どもを教育するかのように、AIを教育する必要があるかもしれません。正しいデータを使いAIを学習すればいいというわけでもありません。正しいデータを使ったからといって、人間が思い描くようなAIになるとは限らないからです。人間社会にとって脅威となるAIが登場するかもしれません。
5、「人類を滅亡させる」と発言
ITmediaに「人類終了のお知らせ AIロボットがついに『人類を滅亡させる』と発言」という記事(2016年3月30日)が掲載されました。Hanson Robotics社が開発した女性型ロボット「Sophia(ソフィア)」が……「OK, I will destroy humans.(そうね、人類を滅亡させるわ)」……と問題発言をしました。その後「冗談よ」とばかりに笑みを浮かべたそうです。「Sophia」は、60種類を超える多様な表情がプログラミングされた女性型のロボットで、アイコンタクトを取りながら表情を変化させ会話をします。つまりAIはデータ環境(教育環境)に大きく依存し、人間が思うように成長するとは限らない、ということです。
6、人間が思うようにできないのは、昔からある問題
この問題は、最近の話ではありません。昔からある問題です。予測モデルや異常検知モデルなどの数理モデル一つとっても、正しくないデータをもとに構築すれば、どこか可笑しなモデルになります。さらに、正しいデータだけで学習させモデルを構築したとしても、思い描いたモデルが構築できるわけではありません。試行錯誤しながら、モデルを構築していきます。実際に、同じデータから作った同じような予測モデルでも、人によって構築されるモデルは異なりますし、モデルの予測精度も異なります。その精度を争うコンペがあるくらいです。
7、データサイエンス全体の問題
この問題は、一部のAIチャットボットや予測モデルの問題ではなく、データサイエンス全体の問題です。正しくないデータが混じっている状態で、ドメインと結びつけざるを得ない状況はいくらでもあります。データサイエンティストの真価が問われます。しか...