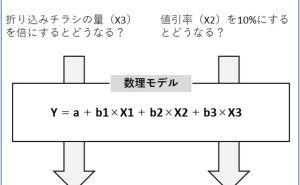
◆ 「すごい分析」よりも「使える分析」
データ分析の手法そのものに、こだわることは決して悪いことではありません。手法やアルゴリズムが発展するほど、分析の幅が広がるからです。しかし、実務の世界では、往々にして「すごい分析=成果の出る」とはなりません。逆に「すごい分析=混乱」となるケースが多々あります。それは、なぜでしょうか?
- 馴染みがなく、理解するのに時間を要するとか
- そもそも、分析者自身がきちんと理解できていないであるとか
- 簡単な分析と比べて、大きなメリットを感じられないとか
色々な理由が考えられます。では、どうすればよいのでしょうか? すごい分析をしてはいけないのでしょうか?
今回は、「『すごい分析』よりも『使える分析』」というお話しをいたします。この「『すごい分析』よりも『使える分析』」という意識が、企業内のデータ分析の成否を大きく左右します。
1. データ分析:手法偏重というトラップ
データ分析に慣れたころ、多くの人がハマるトラップがあります。覚えたての分析手法やアルゴリズムを試したくなるという欲求です。それはそれで悪いことではありません。個人のナレッジもスキルも向上しますし、今まで以上の成果の出る可能性を秘めているからです。しかし、多くの場合、時間ばかり浪費し、浪費した時間以上の成果を生むこともなく、自己満足で終わっているケースも少なくありません。
そして、最悪なケースは、その分析結果を誰も活用しないこと。
例えば、分析に手間取り、思っていた以上に時間がかかり、分析結果の欲しいタイミングに間に合わず、分析結果を心待ちにしていた現場の期待を裏切る。
例えば、分析結果の欲しいタイミングには間に合ったが、分析者がその分析結果の説明をするとき、自分の興味の高いその真新しい分析手法の素晴らしさの話ばかりし、現場に混乱と胡散臭さをもたらし、分析結果の結論があやふやになり、活用イメージが出来ず使われない。
では、どうすればよいのだろうか? 新しい分析手法やアルゴリズムに挑戦することは悪なのだろうか?
2. データ分析:説明できない分析はしない
新しい分析手法やアルゴリズムに挑戦することは悪ではない。しかし、分析者がその挑戦した新しい分析手法やアルゴリズムの分析結果に対し、質問を受けたときに説明できなければアウトであろう。自分自身がよく理解していないものを、他人(分析結果を活用する側)に押し付けても、押し付けられた側は「不安に思う」か「胡散臭く思う」かのどちらかだと思います。
他人(分析結果を活用する側)に活用してもらいたいなら、少なくともその手法について、少なくとも勉強すべきだと思います。そもそも、出力された分析結果の解釈すら出来ないからです。アルゴリズムの数式レベルまで理解する必要はないかもしれませんが、どのようなインプットに対し、どのような処理をし、そしてどのようなアウトプットが出力され、そのアウトプットの数値はどのような意味を持つのかぐらいは、理解しておいたほうが良いと思います。
すこし分析のハードルが上がったように感じる方も多いと多みますが、最近はビジネスパーソン向けの分かりやすい分析手法の本も多数出版されているので、気になる箇所だけでもさらっと読んでおいたほうが良いかと思います。
このとき、学生時代のような学問的な読み方ではなく、実務的な読み方をすることをお勧めします。なぜならば、ビジネスの世界では、実務で使えなければなりません。「実務的な読み方」とは、自分の仕事で扱っているデータで置き換えると、どのような意味を持つのだろうかとか、ビジネス上どのような意味を持つだろうかと考えながら、本を読むということです。
現実の世界とリンクさせながら、分析の本を読むことで、活用イメージを掴むきっかけになります。つまり、「使える分析」はないだろうかと、探りながら読み進めていきます。
3. データ分析:まずは「すごい分析」よりも「使える分析」を目指す
実務でデータ分析を活用するとき、まずは「すごい分析」よりも「使える分析」を目指すべきです。
「すごい分析」とは、真新しい分析手法やアルゴリズム、予測精度などを過度に追求した分析のことです。「すごい分析」を追求することは、それはそれで素晴らしいことですが、活用されなければ無意味になってしまいます。まずは、「使える分析」を目指すべきです。
「使える分析」とは、実務で使ってもらえるデータ分析のことです。そして、ビジネス成果のでるデータ分析のことです。営業やマーケティングであれば、売り上げや利益アップに貢献するデータ分析となることでしょう。
営業やマーケティングでなくとも、データ分析の成果を金額換算することは非常に重要なことです。なぜならば、分かりやすく理解されやすいからです。
実際に、あったケースです。
昔から活用されているレガシーな重回帰モデルで十分なケースで、今流行りのランダムフォレストというアルゴリズムで予測したら精度が良かった。しかし、劇的に精度が向上したわけではない。そこで金額換算したら、何も変わらない。
わかりやすさで言えば、重回帰モデルのほうが分かりやすく、周囲の理解も早い。ただただランダムフォレストを使うことで、データ分析を分かりにくくした。現場からは「なぜ、あえて分かりにくくするのか???」という不満の声がチラホラ……
結局、今流行りのランダムフォレストとともに、昔から活用されているレガシーな重回帰モデルの分析結果も、現場に対し提示することになった…… ランダムフォレストは単なる分析側の自己満足のために実施し、現場で使われているのは重回帰分析。
4. データ分析:余力があれば挑戦するぐらいが、ちょうどいい
多くのデータ分析者は、重回帰分析をできるようになれば、それ以上の分析手法をしたいと思うことでしょう。例え、実務上は重回帰分析で十分であっても……
その効果(ビジネスインパクト)を冷静に見積もってみると、真新しい分析手法を使うことで、大きなビジネスインパクトを見出すことは少ないことでしょう。それでも今までにない価値を得るかもしれないし、そもそも分析者の好奇心は常に真新しい分析手法に目が行きがちです。私の考えですが、余力があれば挑戦するぐらいが、ちょうどいいと思っています。
真新しい分析手法に挑戦し、分析結果を出すタイミングが間に合わず活用されないなど言語道断です。タイミングが間に合っても、小難しすぎて理解されず活用されないのは悲しいことです。では、どうすればよいのか?
挑戦は一旦脇に置いて、まずは「使える分析」を目指します。そして、確実な成果を手にします。そして、余力があれば真新しい分析手法に挑戦する。先ほどの例でいえば、重回帰分析をやります。その上で、余力があれば真新しい分析手法であるランダムフォレストに挑戦する。このとき、報告する順番を間違えてはいけません。先に重回帰分析結果を提示し、補足としてランダムフォレストの結果を提示します。
5. 「すごい分析」よりも「使える分析」という意識
今回は、「『すごい分析』よりも『使える分析』」というお話しをしました。
実際に、この「『すごい分析』よりも『使える分析』」という意識が、企業内のデータ分析の成否を大きく左右しています。研究という位置づけであ...