

法人相手のビジネスやECサイト、個別面談を通すようなビジネスなどでは、顧客をIDベースで追えるケースが多いのです。運が良ければ、リード(見込み顧客)の段階で、何かしらデータを得ているケースもあります。法人相手のビジネスなどは最たる例でしょう。その場合、そのリード(見込み顧客)が顧客になる可能性が分かると非常に嬉しいのです。それは対応すべき優先順位の参考にしたりできるからです。そのためには、リード(見込み顧客)の受注を予測しなければなりません。
このリード(見込み顧客)の受注を予測するためのモデルを、機械学習のアルゴリズムで構築するケースが増えています。今回は「教師なし学習と教師あり学習を使った『リード(見込み顧客)の受注予測』」というお話しをします。
【目次】
1.「教師なし学習」による顧客理解と 「教師あり学習」による予測
2.「教師なし学習」による顧客理解
(1) 異常データを含めるかどうか
(2) 顧客を特徴づける変数は何か
(3) 変数を増やして減らして……
3.リード(見込み顧客)のクラスタリング
(1)顧客の属するクラスターを予測
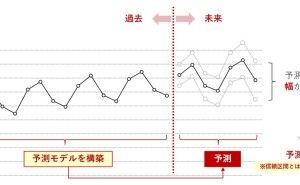
4.リード(見込み顧客)の受注予測モデルの構築
【この連載の前回:データ分析講座(その251)需要予測モデル構築時の検討すべきポイントへのリンク】
1.「教師なし学習」による顧客理解と「教師あり学習」による予測
機械学習のアルゴリズムには、大きく「目的変数のない教師なし学習」と「目的変数のある教師あり学習」があります。他にも、強化学習などありますが、ここでは一旦この2つ「教師なし学習」と「教師あり学習」に絞ってお話しを勧めます。
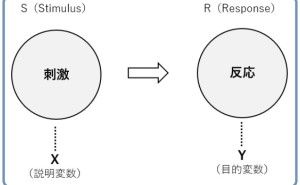
「リード(見込み顧客)の受注予測」をする場合の目的変数は、「受注の有無」です。受注したのか、失注したのかを表す変数です。例えば、受注を「1」、失注を「0」などの数字で表現したりします。受注を表す「1」の確率を予測モデルで、「教師あり学習」のアルゴリズムを使って構築します。
では、「教師なし学習」はどこで使うのか?「教師なし学習」は、例えば、「教師あり学習」で構築する予測モデルを作る前に使ったりします。例えば、以下のような順番です。
- 「教師なし学習」で顧客理解
- 「教師あり学習」で予測モデル構築
2.「教師なし学習」による顧客理解
「教師なし学習」の代表的なアルゴリズムは、例えば以下です。
- 異常データの検出
- 主成分分析/因子分析(次元削減・集約)
- クラスタリング
これらのアルゴリズムを使った顧客理解方法を紹介します。今回紹介するのは一例です。
(1) 異常データを含めるかどうか
異常検知なども含めた「異常データの検出」のためのアルゴリズムには、どのデータがどのような異常なのかというラベルのある「教師あり学習」と、ラベルのない「教師なし学習」があります。「教師なし学習」による「異常データの検出」は、仲間はずれを探す、という感じです。
例えば、10万レコードのデータセットがあって、ある1レコードだけ他のどのレコードとも全く似ていないのなら異常かもしれない、と考えるということです。
異常スコアのようなものが出力されますので、そのスコアの高いレコードに対し、ありえるデータなのか、ありえないデータなのか、データセットに混ぜるべきか、起こり得ない事例として除外すべきか、を検討する必要があります。
最近では、Random Forest(ランダムフォレスト)ベースのIsolation Forestが、よく利用されている印象があります。他にも、One-class SVMやLocal Outlier Factorなど色々なアルゴリズムがあります。
(2) 顧客を特徴づける変数は何か
例外的な異常データを取り除いたデータセットに対し、リード(見込み顧客)のデータセットと顧客のデータセットで共通する変数を比べます。例えば、2つのデータセットの分布(量的変数であればヒストグラム)を作り比べ、同じ分布とみなせるのか?別の分布とみなせるのか?を検討し顧客の特徴を考えていきます。
例えば、ある2つの分布が一致しているかどうかを調べるために、KS検定(Kolmogorov-Smirnov test、コルモゴロフ・スミルノフ検定)を実施したりします。別の分布とみなせる変数から順番に、グラフ化しどのような違いが生じていそうかを解釈していきます。リード(見込み顧客)と顧客の違いから、顧客の特徴を把握することができます。
(3) 変数を増やして減らして
リード(見込み顧客)をグルーピングするために、リード(見込み顧客)のデータセットに対しクラスタリングを実施(クラスター分析)していきます。
その前処理として、例えば、One Hot Encoding、主成分分析/因子分析を実施したりします。
One Hot Encodingを実施することで、カテゴリカル変数を0-1データにしていきます。この処理によって、変数の数がそれなりに増えます。主成分分析や因子分析を実施することで、変数の数を減らしていきます(次元削減・集約)。ここでポイントになるのは、顧客の特徴を表現する変数(厳密には主成分)は削らないようにする、ということです。
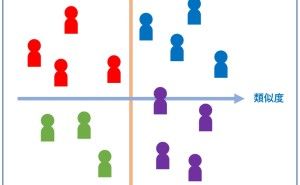
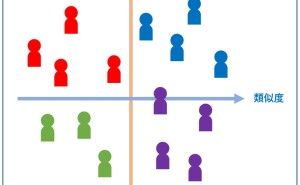
3.リード(見込み顧客)のクラスタリング
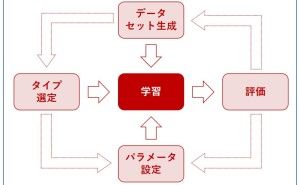
次に、リード(見込み顧客)をグルーピング(クラスタリング)するために、クラスタ分析を実施していきます。クラスタリングのアルゴリズムは、階層型でも非階層型でも何でも構いません。クラスタ分析を実施すると、幾つかのクラスターにリード(見込み顧客)が分類されるかと思います。
そのクラスターの特徴を把握するために、クラスター別に変数を集計し見比べてもいいでしょう。そこでポイントが1つあります。それは、先程述べた「2つのデータセットを見比べて把握した顧客の特徴」を持ったクラスターがあるかどうかです。
そのような特徴をもったクラスターがある場合は、次に進みます。無い場合には、クラスタリング方法を再検討してください。クラスター数を変える、アルゴリズムを変えるなどです。
(1) 顧客の属するクラスターを予測
いい感じで、リード(見込み顧客)をクラスタリングできたら、次に各顧客がどのクラスターに所属するのかを予測し、各顧客をクラスターに振り分けます。リード(見込み顧客)のクラスタ分析の結果(クラスタリングルール)を使って、顧客を振り分けるということです。
クラスター分析を実施したときに、クラスターを予測するクラスター予測モデルが一緒に構築されているのなら、そのクラスター予測モデルをそのまま使って、各顧客がどのクラスターに属するのか予測します。クラスター予測モデルが無いのであれば、「教師あり学習」の分類問題系のアルゴリズム(例:ロジスティック回帰など)を使って、クラスター予測モデルを、リード(見込み顧客)のデータセットを使って構築します。
何はともあれ、リード(見込み顧客)のクラスターに、各顧客を振り分けることができるはずです。振り分けたら、どのクラスターに顧客がより多く振り分けられたのかを分析しましょう。単純に、N数比較でも十分です。
多くの場合、特定のクラスターに多く振り分けられます。その特定のクラスターに属するリード(見込み顧客)は、おそらく顧客になりやすいリード(見込み顧客)です。そして、その特定のクラスターを特徴づける変数が、リード(見込み顧客)の受注予測モデルを構築するときの、非常に重要な特徴量(説明変数)となることでしょう。










































































































































































































































































-その原点を考える")








