◆ ロジスティック回帰分析を含めた判別分析、正答率と検出率のどちらを重視?
受注予測や離反予測など、判別分析の出番が意外と多いのがビジネスデータ分析の特徴です。受注や離反だけでなく、状態遷移(例:訪問→提案)の予測も判別分析の範疇(はんちゅう)です。昔から色々な判別分析の手法があります。
共通しているのは、学習データで分類モデルを構築し、混合行列(confusion matrix)で評価するということです。この時、混合行列には幾つかの指標があり、どれを見ればいいのか迷う人も多いようです。
今回は「ロジスティック回帰分析を含めた判別分析、正答率と検出率のどちらを重視しますか」というお話しです。
1. 判別分析
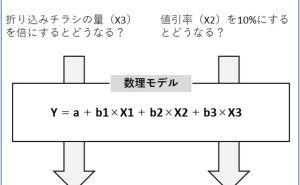
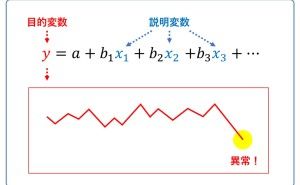
判別分析とは、2つのカテゴリ(例:受注 or 失注)を予測する分類モデルを構築するものです。昔からあるのは、線形判別分析などの多変量解析やロジスティック回帰などの一般化線形モデル系のものです。
20年ぐらい前から、サポートベクターマシーン(SVM)などのカーネル多変量解析系や決定木、ニューラルネットワークなどの機械学習系のものが使われ始めましたが、どの手法で分類モデルを構築しても得たい結果は同じです。
どの手法で分類モデルを構築しても多くの場合、混合行列を使うようです。モデルの良し悪しを評価する際、必ずといっていいほど混合行列が登場してきます。
2. 混合行列
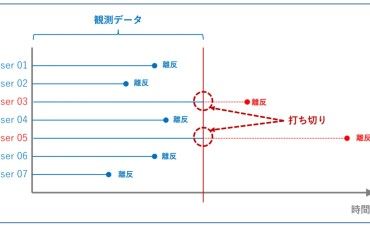
混合行列とは予測と実測のマトリックスです。次のようになります。
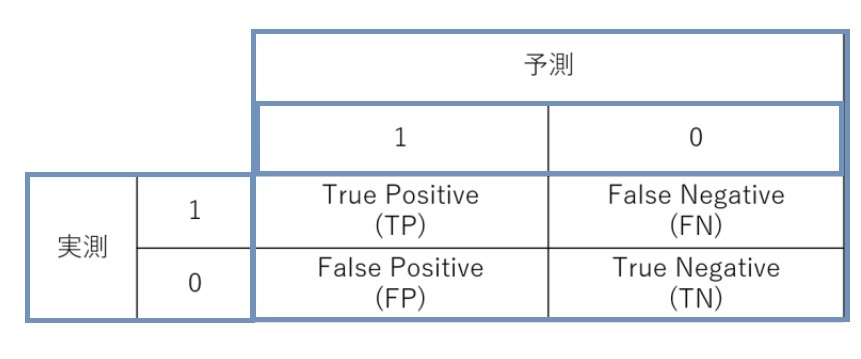
分析ターゲットが通常は「1」になります(例:受注が分析ターゲットであれば受注が「1」、離脱がターゲットであれば離脱が「1」)。
例えば、分析ターゲットが受注とし「1:受注、0:失注」とします。この時、実際に受注し分類モデルでも受注と予測された件数が「True Positive(TP)」に入ります。
「TP」と「True Negative (TN)」が正答した件数です。全件数は、4つのセルの合計値「TP+FN+FP+TN」になります。
この時、正答率は「(TP+TN)÷(TP+FN+FP+TN)」となります。
通常考えると「正答率が高くなるような分類モデルがいいのではないか?」と考えがちです。しかし必ずしも正答率が高いモデルが実務上活用できるモデルとは限りません。
3. 4つの指標
混合行列(confusion matrix)には、4つの指標が計算されます。
- 正答率:(TP+TN)÷(TP+FN+FP+TN)
- 検出率:TP÷(TP+FN)
- 精度:TP÷(TP+FP)
- 誤検出率:FP÷(FP+TN)
正答率とは先ほど話した通り、正答した割合です。検出率とは実測が「1:受注」のケースを分類モデルがどれほどカバーしたのかを表したものです。実測が「1:受注」の件数は「TP+FN」です。このうちモデルが的中したのは「TP」です。したがって、検出率は「TP÷(TP+FN)」となります。実は正答率よりも検出率のほうが実務上、重要になってきます。どんなに正答率が良くても、検出率が悪いと使いものにならないからです。
4. 正答率90%で検出率0%の残念な分類モデル
実際、私は正答率90%で検出率0%の残念な分類モデルを見たことがあります。
検出率0%ということは、受注予測モデルであれば「実際は受注しているのに、受注していると予測されない」ということです。0%なので、一つも受注ではなく失注と予測されます。分析ターゲットが「離反」であれば、全く離反を予測しないことになります。どんなに正答率が高くても、分析ターゲットを検出できないようでは実務では使えません。実際何が起こっているのでしょうか?
5. 学習データが偏っている場合、要注意
なぜ「正答率90%で検出率0%」などということが起こるのでしょうか?それは学習データが偏っている場合です。偏っているとは、先ほどの例で説明すると「1:受注」のデータが全体の10%で「0:失注」のデータが全体の90%のようなものです。この時、すべてを失注と予測するモデルを構築すれば、正答率は90%になります。このようなモデルを作るのは簡単ですが検出率は0%になります。
6. ウエイトバックとは
少しテクニカルな話題になります。学習データが偏っている場合、ウエイトバック(※1)をしてからモデル構築をします。特別な理由がない限り、そうしたほうが無難です。特別な場合とは、データの偏り自体がモデル構築上重要な場合です。
実は、従...